
Updated: Category: Cloud
Obviously, serverless technologies aren’t an illusion. They are quite real. AWS kicked off serverless in 2014 with the launch of Lambda, which remains the category-defining service to date. Since then “serverless” has taken on a much broader meaning and virtually every cloud provider offers serverless run-times, databases, and integration services. So where’s the illusion?
Building Abstractions Instead of Illusions
As I discussed in a prior post (which since expanded into a talk and a chapter in Platform Strategy), illusions happen when abstractions hide relevant concepts and therefore set false expectations, for example, if a distributed system that is subject to latency and out-of-order delivery pretends to be just like a local system that doesn’t exhibit these run-time challenges. Developers may enjoy their initial, seemingly simplified, experience until inevitably the illusion pops and things break without them having much of an idea why. In a way, software illusions are the antithesis of mechanical sympathy: they pretend that the system is something that it isn’t and likely can’t be.
So, where does serverless fall into this trap? Doesn’t it do a nice job abstracting away infrastructure, so you can focus on writing business logic and providing value instead of toiling in the operational engine room, doing undifferentiated heavy lifting? Before we reveal that part, let’s take a tiny step back and look at serverless tech in context.
Serverless is awesome
I routinely pitch serverless as follows:
Serverless is the real cloud native way because it’s how the cloud wants you to build applications.
Serverless (specifically Functions-as-a-Service) provides the highest level of run-abstraction: you write a function, deploy it, and invoke it. The infrastructure figures out where your code (or image) should reside, which host to run it on, and how to route requests to it. This process is so seamless that it’s easy to forget how awesome it is (or perhaps how cumbersome it was before).
My first triumph with this kind of instant-deployment technology that allows you to forget about servers was in 2009, a full 5 years before Lambda. During a JavaOne panel on cloud computing, my fellow panelists showed slides explaining how awesome the cloud is. I instead fired up an IDE, typed a few lines of code, and deployed them to a public URL, using Google App Engine at the time. App Engine was a big step ahead (I still have my T-shirt), but it also came with several constraints that restricted what kind of applications you could run.
So, serverless is awesome. But we should also reflect how the higher-level run-time abstraction influences the programming model, so we don’t end up with illusions.
Run-Time Illusions
A function-as-a-service function isn’t a like local method. It runs distributed, invoked via a queue, under resource constraints that are managed by an auto-scaling mechanism. The best-known symptom of a cloud function is cold starts. Cold starts occur when no instances of the function are available and a new environment to execute the function has to start up. Cold starts cause latency spikes, increasing latency typically by a multiple despite clever approaches like Lambda SnapStart and GCP CPU Boost. If you use serverless functions for anything but demo apps, you should consider cold starts. Yan Cui wrote an insightful post on Lambda cold starts several years ago.
Cold start’s ugly cousin is throttling, which happens when incoming requests exceed the number of available function instances. Invoking a function whose concurrency is exhausted, results in a 429–Too Many Requests exception. The existence of a standard HTTP response status code hints that such an error isn’t unique to serverless functions but fundamental behavior of distributed systems. The mechanism behind that error, load shedding, is actually essential to handling high load situations gracefully. But it’s also an error that local methods don’t have.
AWS’ recommended settings for managing cold starts and throttling are Reserved and Provisioned Concurrency, which roughly translates into the number of instances a function can use under high traffic and the number of instances that are always active even when traffic is low. The documentation explains in detail how to manage these settings. Similarly, push subscriptions in GCP Pub/Sub have a robust but also complex scaling behavior. Building such systems requires a good amount of RTFM.
The Simplicity Illusion
The documentation on concurrency settings is excellent, but it’s also dozens of pages. Polylith applications (my word creation of the day to denote something that’s not a monolith but also not fine-grained until I found out the term’s already taken), perhaps deployed inside a container, don’t require such run-time management (nor the associated documentation) to make a function call.
Serverless applications favor fine-grained, distributed, and concurrent architectures. While that gives them desirable operational characteristics like resilience and auto-scaling, it also implies complex design and run-time considerations. Developers have to configure and integrate numerous components including access control at design-time, often with little language support. They also have to account for out-of-order or duplicate message delivery and perform retry logic. At run-time, developers have to manage scaling, quotas, queue sizes, dead-letter queues, poison messages, just to name a few.
To make things even more “interesting”, not all the run-time elements are directly visible to the developer, for example invocation queues and retry logic with exponential back-off. These “built-in” elements increase system resilience but also influence system behavior like latency and therefore can’t be ignored.
Building serverless solutions reduces operational effort to manage resources. But coding such applications is complex as you’re facing the realities of fine-grained, asynchronous systems. Now you could argue that without serverless you’d have both: operational toil and the distributed complexities, but in reality you’d be less likely to build such a fine-grained architecture if you’re managing infrastructure yourself.
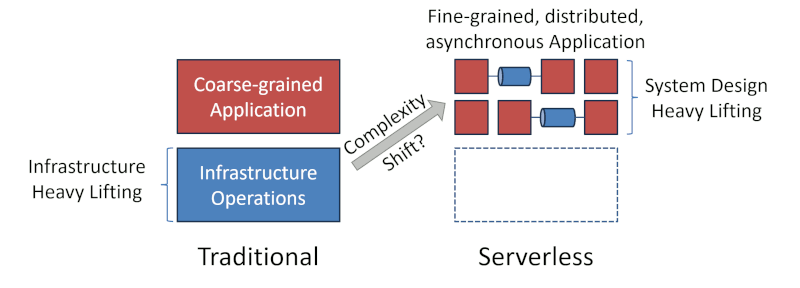
As a reward for reading this far despite the click-bait title, you shall be rewarded with what I provocatively call the “serverless illusion”:
Serverless reduces the need for (readily available) ops skills but increases the demand for (less readily available) distributed system design skills.
Virtual machine and database operations isn’t simple, but it’s a task that traditional IT teams have been carrying out for decades. Serverless dramatically reduces the need for such operational toil. But it requires deep knowledge of dynamic distributed system behavior and the related platform-specific settings. That’s a skill set that is much harder (or more pricey) to come by.
Is Ops Really “Undifferentiated”?
Infrastructure ops are “undifferentiated” because the time spent there could be invested in building functionality that delivers satisfied users and business value. That doesn’t mean the ops heavy lifting isn’t valuable–if your app doesn’t perform, users may never get to see that exciting functionality you built. The main argument is that you can focus on application-level tasks by letting the cloud provider handle operations.
But here lies the catch. There are plenty of operational tasks left for serverless teams to tackle. They are just at a higher level of abstraction, so you’re dealing with a different set of problems. You could argue whether dealing with such distributed system complexity is more “differentiated” than dealing with infrastructure. Both are needed to maintain system availability, but neither is building features.
A fine-grained, asynchronous application is likely more resilient and cost-effective than a monolith running on VMs. But it may be harder to build and operate.
What if I Want the Functionality but not the Distributedness?
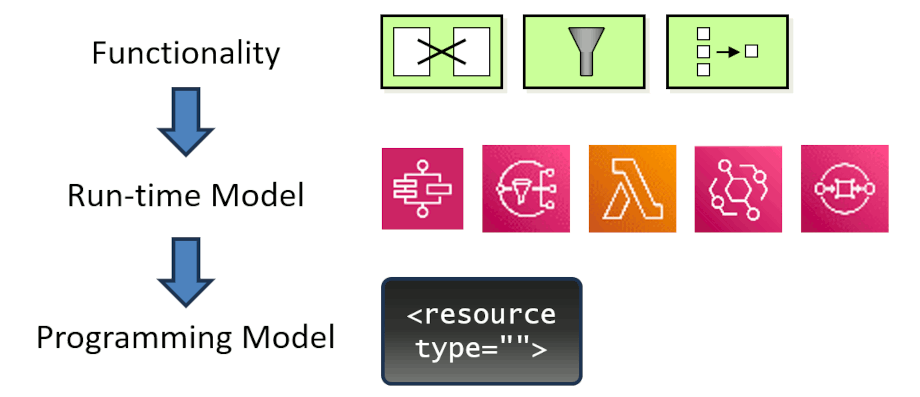
Most serverless setups provide additional functions, for example for event routing and filtering, data streaming, APIs access, or higher-level services like pre-trained machine learning models for image recognition. Having such an ecosystem is a strength of serverless cloud environments (and the reason I advise to not evaluate cloud platforms by single features). But these functions are packaged in stand-alone services, requiring developers to form a valid API request, handle error codes, and get IAM setup so that the call actually goes through. Once that’s all done, they must configure logging and related functions.
This form of run-time composition has tremendous operational advantages, but it’s more complex than design-time composition, which simply calls a library function. Sometimes I just want to run a set of predicates over a JSON object without having to configure an entire event router service and the associated permissions and limitations. Put another way:
What if I want the functionality but not the distributedness?
That might be the case because I am testing, or because my app has limited (or predictable) scalability needs. Using the mental model of an architect, I’d characterize the challenge as follows:
Serverless marries functionality with the run-time model.
If I want to access specific behavior, I need to accept the associated run-time model. This is a strong form of coupling between functionality and run-time architecture that can cause complexity even in cases when it’s not delivering much value.
The inverse coupling ties the availability of functionality to specific run-time characteristics, for example pull-vs-push control flow. For example, to use an Enricher in AWS-land (I am using AWS as an example because I know it better), you have to use EventBridge Pipes , which implies a “pull” control flow. A “push” control flow requires an EventBridge Bus, which doesn’t support an Enrichment step. There are valid reasons underneath, but having to know the control flow to use a piece of functionality doesn’t make a developer’s live simpler.
Can I Have my Serverless Cake and Eat it too?
Folks have noticed that composing distributed systems in the cloud isn’t particularly easy, so we are starting to see efforts to improve the quality of live of serverless developers. Approaches tend to fall into two categories:
- Simplify composition
- Reduce composition by allowing more coarse-grained components
The more fine-grained your system is, the more relevant the lines between the components become. As explained in a previous post, making composition a first-class concern is paramount to reducing the complexity of coding serverless applications. This shift is at the core of my work on Architecture as Code.
If you want serverless to not be an illusion, code to the lines, not the boxes!
Azure Aspire is another approach to make describing the applications easier. Durable functions overcome the serverless run-time limits and look to simplify the programming model. GCP increased the Cloud Functions run-time to 1h and instance sizes to 16 GB to allow the serverless application architecture to be a less fine-grained and hence easier to manage.
A monolithic programming model for distributed applications
An undesirable side-effect of programming to the run-time model is that you end up with a distributed programming model, which loads you up with a ton of cognitive load, aka “mental heavy lifting”. Detaching the programming model from the individual cloud services reduces the amount of infrastructure complexity that shifts to the programming model.
This approach was best summarized by Elad Ben-Israel (creator of CDK and founder of Wing) during a Twitter/X discussion (that platform is apparently still good for something):
I want a monolithic programming model for a distributed application
For fairness’ sake, other folks are working in the same space, so I should mention Jeremy Daly’s Ampt as an example. The core concept is to code your application in a uniform code base that describes the application as a whole as opposed to a collection of individual services that are wired together through string values.
I find this approach most promising with the key question being on what baseline to build such a programming model. Winglang and Ampt start from a clean slate whereas my AaC efforts test how far we can get on top of existing tools like CDK.
Most approaches utilize the type system of our automation languages to replace the current stringly typed approach. Very little of the run-time behavior of the current cloud services is represented in the type system. You can connect most any resource to any other, and they will deploy fine, but they won’t run, at least not in the sense that you’d expect. Finding this out at run-time is the antithesis of a delightful developer experience.
Simple vs. Intuitive vs. AI
Aside from the technical choices, we can utilize three different levers to make serverless development delightful:
- Make it simpler
- Make it more intuitive
- Let GenAI deal with it
Distributed system development isn’t simple. Most attempts to make it look simple end up being illusions or forfeit essential properties such as concurrent processing. But I feel that distributed system development in a serverless context can be much more intuitive. Intuitive programming models generate a system that behaves the way a developer would expect (without having to read reams of documentation.)
On the other end of the spectrum, GenAI can make us more productive in overcoming these hurdles, but it’s still largely up to us to define the underlying model on which the code operates, e.g. a shift from resource hierarchies to control flow.
Who will lead the pack?
It can take time for platform companies to fully internalize what they have actually built. Much activity and innovation in the space of simplifying the serverless developer experience model is driven by start-up companies as opposed to the traditional cloud providers. From the latter pack, Azure appears to be most keen to tackle the challenge. Still, it’s a valid question whether cloud providers are better equipped to build robust and scalable run-times as opposed to stellar developer experiences:
A shift in run-time model implies a shift in programming model. Driving innovation in both areas requires a diverse skill set and focus.
If major cloud providers don’t drive innovation in this area, they may ultimately be commoditized as run-time providers. Developers will then choose the best programming model as opposed to the best run-time (and possibly having an independent choice for the latter).
Thanks to Yan Cui, Philipp Garbe, and Mike Roberts for early feedback and input on this article.

Platforms appear to defy the laws of physics by boosting velocity and innovation via standardization and harmonization. Pulling this magic off is harder than it looks, so before you embark on your platform journey, equip yourself with this valuable guide from the Architect Elevator book series.
Grow Your Impact as an Architect

The Software Architect Elevator helps architects and IT professionals to take their role to the next level. By sharing the real-life journey of a chief architect, it shows how to influence organizations at the intersection of business and technology. Buy it on Amazon US, Amazon UK, Amazon Europe



