
Updated: Category: Cloud
Automation is an essential part of cloud computing. Because it’s hard to imagine a successful cloud project that doesn’t use automation, I’ve been known to clearly state my view that:
Cloud without automation is just another data center
As it usually happens, the critical role that cloud automation plays comes with a flurry of ever-evolving options, strong opinions, hyperbole, and confusion. One trend is clear, though: as run-time models abstract away more of the infrastructure management, the role of cloud automation also shifts towards applications. That shift isn’t linear, though, but looks at things from a whole new dimension. And once again it has to do with boxes and lines. Allow me to explain…
Quo Vadis, IaC?
The modern era of cloud automation tools started in 2011 with AWS CloudFormation (5 years after S3 and EC2, no less), followed by Hashicorp’s Terraform in 2014. A few years later, in 2018, Pulumi made cloud automation possible in general purpose languages, making the “C” in the “IaC” label real. AWS CDK quickly followed in 2019.
With cloud automation languages having been around for a decade or so, you’d expect this space to be mostly settled, aside from supporting new resource types. And, indeed, you’ll find well-established factions (more on those later) that strongly prefer one tool or another.
However, there is notable movement in cloud automation in the past two years: AWS CDK got a bump to v2 at the end of 2021, followed by the general availability of CDKTF in late 2022. A bolder addition is the Cue language, which has a broader scope than just automation and has some really nifty features like treating types and ranges as values. Established languages are also getting a boost, with CloudFormation being augmented by a loop construct called ForEach in July 2023 (and re-triggering the debate on declarative vs. procedural programming).
The biggest buzz in 2023 isn’t around a new automation language, though, it’s the notion that you won’t need a separate automation language at all because you can instead derive all you need from your application code. Welcome Infrastructure from Code! In some implementations, this application code is written in a new language like Wing or DarkLang whereas others like Klotho use established languages like Javascript with custom frameworks or annotations. Klotho’s State of Infrastructure-from-Code 2023 gives a fairly balanced overview of the different approaches.
Infrastructure from Code (IfC) = cloud resource deployment and configuration is driven from application code, rendering explicit cloud automation redundant
The new approach surely sounds exciting, but it can also be confusing as much of the documentation is biased towards one direction or another. The following note on the Wikipedia page for Infrastructure as Code sums up the state of affairs:
Wikipedia on IaC: This article contains content that is written like an advertisement. (March 2018)
To get a clearer view on cloud automation, a little architecture thinking turns out to be rather helpful.
Automation: Seeing More Dimensions
If you talk to any large organization that’s using the cloud, you are likely to find strong views on the “ideal” cloud automation framework. You may find warring factions in the same company, typically in the form of infrastructure teams being deeply embedded in Terraform-land whereas application teams, especially those writing serverless applications, are eyeing CDK or even IfC tools. One side will proclaim impending doom when developers can write buggy code that deploys thousands of instances. If that doesn’t suffice, they’ll cite CDK being non-deterministic (it’s actually as deterministic as any other Python or JavaScript code). The other side fires back by pointing to thousands of lines of fragile YAML code that cause even minor changes to take several weeks due to the lack of automated tests. Common ground is difficult to come by.
The strong, and often opposing, opinions are generally the result of cloud automation performing multiple tasks. Depending on which task is a person’s main focus, different languages and approaches will seem better suited. The problems arise when each person claims to have found the “best approach” without considering the context. It’s a classic case of people not seeing all dimensions . Following my own advice, the chapter on “IaaC - Infrastructure as actual Code” in my book Cloud Strategy (you’ll find a discount code on that page) breaks down automation into four dimensions:
- Provision Resources
- Deploy application Artifacts
- Compose Connections
- Specify Settings
Cloud automation’s history lies in resource provisioning: VMs, databases, storage buckets. But resources without applications just rack up your cloud bill, so your automation better deploy some app images, containers, or serverless functions. Those application components don’t live in isolation, so they need to be wired together, e.g. to provide a reference to a database to a function or to connect a function to a message queue. This is mostly done with resource references / ARNs, which I commented on in my previous post. Last, many deployed applications take additional parameters, whether it’s for business logic, green/blue deployments, A/B testing, or the like. Some of these will come from a configuration service or a secret manager whereas others are included in the automation scripts.
Cloud Automation isn’t about Infrastructure
Cloud automation’s traditional focus on resource provisioning drove the automation language design. A document-oriented language like JSON or YAML works well to describe the properties of an infrastructure resource. However, serverless applications make us rethink the role of automation and the shift can be easily expressed along the four dimensions of cloud automation cited above. Infrastructure resource provisioning is obviously less relevant in a run-time model that frees developers from worrying about infrastructure.
That’s why I have on occasion pointed out that the “I” in IaC is misnomer for most modern cloud automation:
Serverless automation isn’t (just) about infrastructure.
Or, to make it more punchy and memorable (and perhaps slightly controversial):
There is no “i” in IaC
Clever slogans aside, what difference does it make if we elevate cloud automation to focus on the application instead of infrastructure? Isn’t it still just a collection of resources, although now it’s serverless functions as opposed to VMs? Yes, technically it’s still resources but the shift is more fundamental than it might at first appear.
The critical shift is twofold:
- Because application-level automation deals with more, finer-grained components, the relationship between the components becomes an important design consideration
- Serverless resources like serverless integration feature application-level configuration, e.g. to filter or transform message formats.
When you have a handful of large components, the way they are connected often isn’t that original. You might have an API gateway, load balancer, virtual machines, and databases / storage.
You deploy your application artifacts on top of the virtual machines. Those applications interact with the data store, but the exact nature of that interaction may be perceived as less relevant. This is classic “IaC” with an uppercase “I”: automation manages infrastructure, leaving the application details to the development teams.
However, if you deploy serverless functions, the way that these functions are connected becomes quite relevant because it has a direct effect on application characteristics like latency, throughput, or resilience:
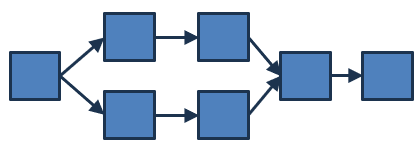
When looking at this diagram, I’d want to know more about the arrows: do they depict the data flow or the control flow (when poling, these point in opposite directions!)? Is this a synchronous or an asynchronous invocation? When two arrows go out from a component, is this a Content-Based Router, a Recipient List, or a Publish-Subscribe Channel where the message goes to all recipients? Is there authentication, retries, queuing, deduplication? By now I have shared almost every slide from my re:Invent API308 talk on distributed system design, so here’s another, very relevant one that summarizes what’s all behind these lines:
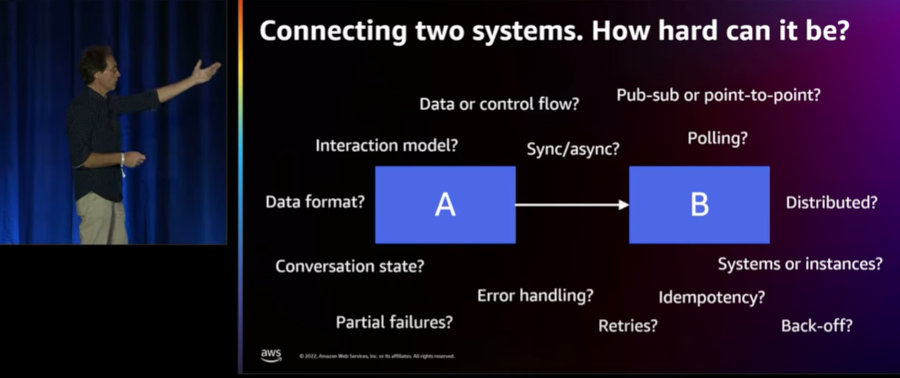
Seeing how much there is behind a single line, we can easily conclude that:
As cloud applications become more fine-grained, the lines are becoming more important.
If you need a punchy example, rewind the video above by 2 minutes to see my favorite example taken from The Software Architect Elevator:
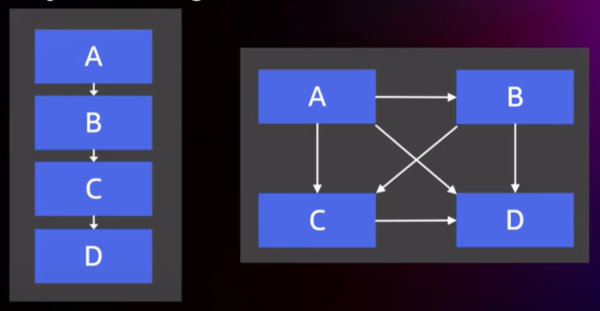
Both systems use the same components but are wired together differently. Would these systems have different properties? Listen to the answer.
Lines = Serverless Services
Serverless isn’t just about deploying functions, though. Most modern clouds now offer orchestration, event routing, and messaging services. These services often represent lines, not boxes in the above diagram:
Traditional cloud services were boxes. Many serverless services are actually lines.
Close to my home, you might look at EventBridge Buses, EventBridge Pipes or Step Functions. which represent an event broker, a polling connector, and an orchestrator. All are connecting elements. The EventBridge Bus documentation states that “an event bus is a pipeline”, which has the word “line” right in it.
These services blur the lines between provisioning and configuration in the four-level model above. For example, you’d “create” an event bus or event matching rules (that’s the language used in the console or the documentation), but without configuration provisioning such a service is rather meaningless. The rule configuration is clearly an application-level exercise as you specify predicates to be applied against messages and route them to different endpoints, such as your serverless functions.
Serverless services are configured as opposed to provisioned. Much of that configuration pertains to the application level.
The Pyramid Principle: Resource Graphs
What do the boxes and lines have to do with cloud automation? Actually, quite a bit. The cheeky section title, which pokes fun at the like-titled book, gives a hint (the book is actually very good but for some reason avoids the word “hierarchy” in favor of “pyramid”).
Typical cloud resource graphs are arranged in a hierarchy: resources are grouped into VMs, subnets, VPCs, accounts, availability zones, and geographic regions. Such groupings make sense as they can define the physical structure of the solution (i.e. where components run), the cost structure (represented as accounts), and the security architecture (network boundaries and access control). The prevalence of hierarchical structures is well represented in the abundance of grouping types in typical cloud architecture diagrams, as taken here from the AWS Architecture Diagram template (as usual, I pick on my own brand here, so in case anyone gets offended, we have shorter lines of communication):

These templates make it easy to draw nested groupings of resources. As discussed in the chapter “Drawing the Line” in The Software Architect Elevator, the semantics behind the dotted rectangles are containment. A secondary concept is that of proximity (two boxes being close to each other), but that doesn’t carry any meaning in the cloud architecture diagrams I have seen (size fell victim to the desire for uniformity, so it also carries no meaning in these pictures). In summary, the nested rectangles are equivalent to a hierarchy or tree (for the graph-inclined) or pyramid (see above):

The two images represent exactly the same structure. As also outlined in the same chapter (I guess I was mentally ahead of myself when I wrote the first draft of that chapter in 2016), the structure is also equivalent to the following textual representation consisting of indented bullet points:
- E
- C
- D
- A
- B
All it takes is a few extra colons or double quotes, and you’ll have a valid YAML or JSON document!
Cloud resource graphs map well to document-oriented languages like JSON or YAML.
People who consider cloud architecture from the point of security, physical locality, or cost accounting will find hierarchical representations very useful. It’s no surprise, then, that they favor languages like Terraform or CloudFormation whose document-oriented style directly represents a hierarchical data structure that describes the cloud resource graph. They often don’t see the appeal of an object-oriented language, and they might be right: a Python or TypeScript program might actually obscure that hierarchical structure and give you one more level of indirection that you didn’t ask for.
Drawing the Line
All non-trivial graphs contain lines (“edges” we might say), but these lines can represent very different things. The punchline of the “Drawing the Line” chapter is as follows:
If I see an architecture diagram without lines, I am inclined to reject it.
Luckily, common cloud diagrams don’t fail this test entirely because they do contain lines. But in stark contrast to the colorful variety of groupings, the rules around lines are rather strict:

That means you’re stuck with using open-headed, 1pt-width, medium gray-with-an-ever-so-slight-blue-tint (#545B64) arrows in a sea of colorful boxes. Feeding off my love for lines, let’s pick an IoT reference architecture diagram straight from the web site:
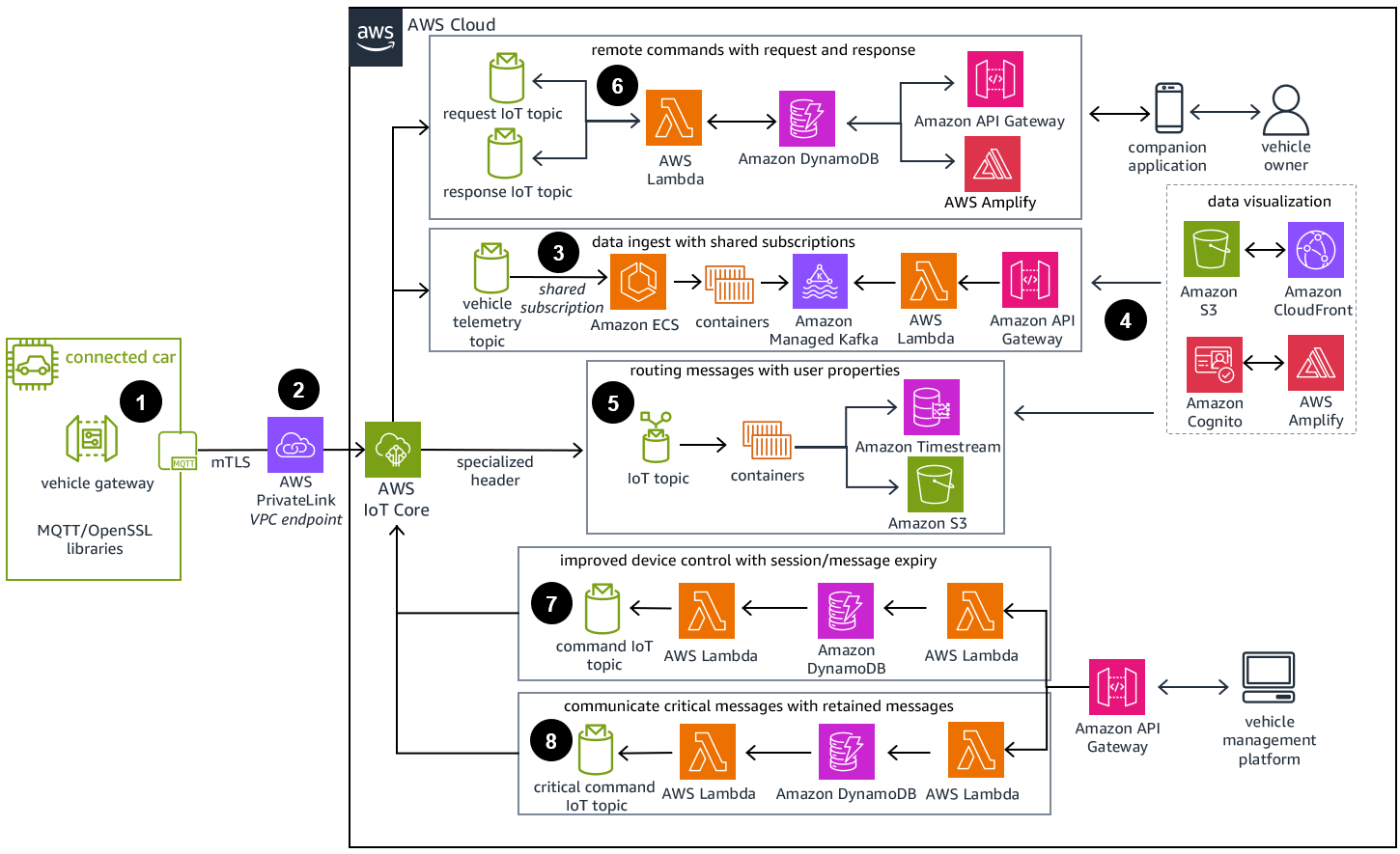
As expected, this diagram, which uses a lot of serverless components, goes easy on groupings, but includes plenty of lines! It even goes as far as–gasp!–using a much darker shade of gray (#232F3C to be exact)–for said lines.
Always keen to peek outside the (corporate) box, I took a quick peek at one of Azure’s IoT diagrams and found just a few small boxes (that appear to depict logical groupings) but a healthy dose of lines:
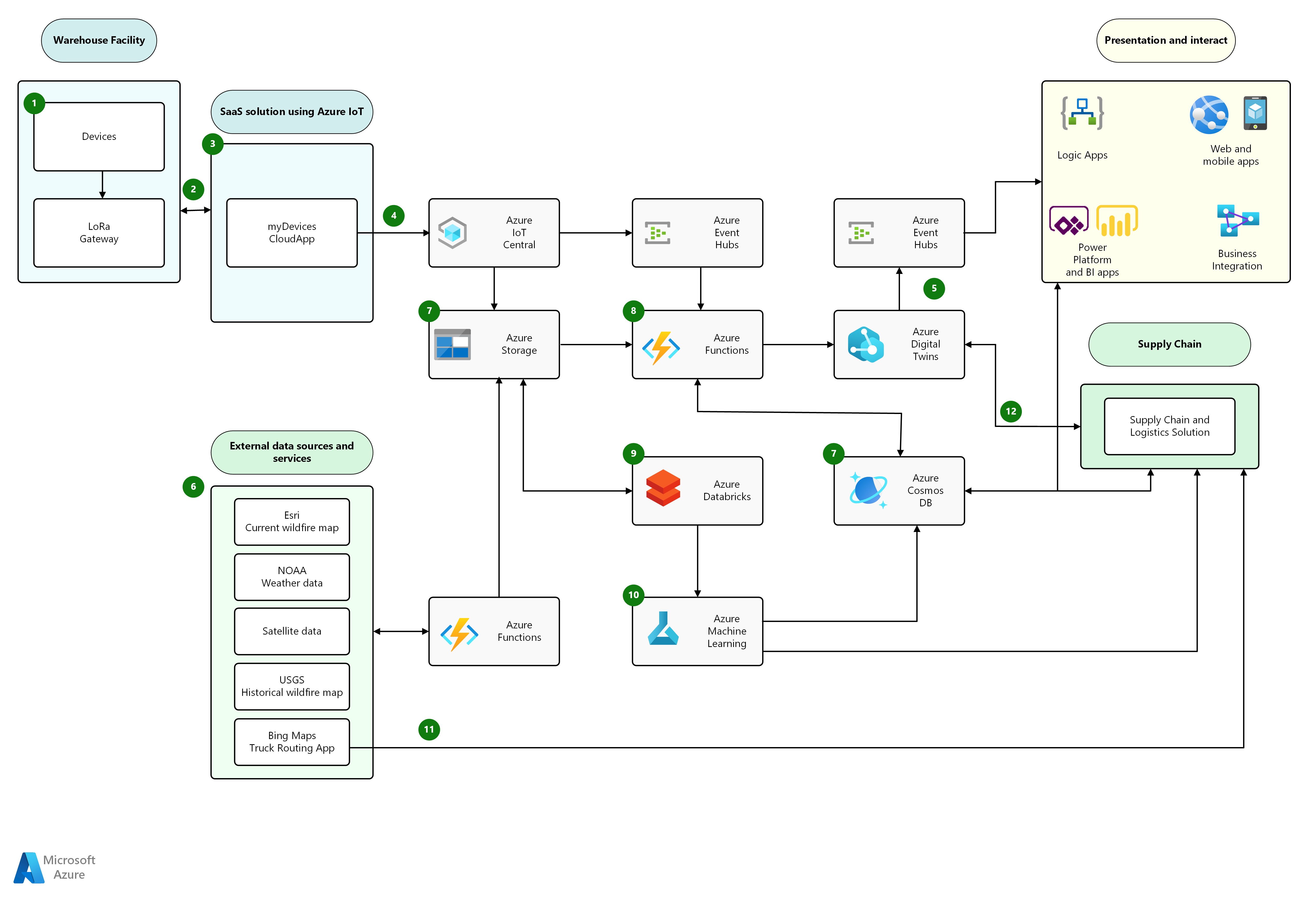
As one might expect, Azure uses a Visio stencil for diagrams that appear to be a bit more flexible when it comes to lines [Azure collects additional points for starting their architecture description with the “Dataflow” and describing the document as a “solution idea” not a “pattern”].
And to complete the set, GCP features its own browser-based drawing tool, which appears quite happy to have you style the lines in pretty much any way you’d prefer:
Before this post starts to feel like a review of diagramming tools, let’s return to automation, but not before I point out that looking at diagrams tells you a lot about a system’s architecture. This train of thought is elaborated in the chapter “Diagram-Driven Design” in–you guessed it–The Software Architect Elevator (yes, you should read it if you haven’t).
Cloud Application Architecture: Containment or Data Flow?
The serverless architecture diagrams above highlight the data flow over the resource hierarchy. Such a depiction is very much in line with the Pipes-and-Filters architectural style that underlies most messaging architectures. Containment between elements as suggested by grouping is often a secondary concern in these solutions. That doesn’t mean it’s less important and a good architecture description will likely use multiple viewpoints. However, an automation language would need to pick one primary viewpoint (unless it equips itself with projections a la Intentional Programming).
So, if we had to pick one or another, fine-grained serverless applications would pick the relationship between components, for example as a data or control flow (perhaps in the same sense that cats would buy a certain brand of food). As my previous post highlights, those relationships are generally poorly modeled in traditional automation languages that focus on resource graphs. Worse yet, they are sometimes buried in the application code that reads passed in environment parameters to decide which queue to publish a message on or which serverless function to invoke next (fixing this is the goal of my Refactoring to Serverless narrative).
Document-oriented automation languages don’t represent data or control flow across application components well.
That’s where object-oriented automation languages show their strengths. Object languages can expose fluent interfaces that make for great internal DSLs. Fluent interfaces are particularly well-suited towards expressing pipes-and-filter chains as these are linear constructs,
Using pseudo-code, and imagining pre-built cloud components that implement popular integration patterns, such an automation script could look as follows:
p = new pipeline()
.fromSource(...)
.via(Filters.MessageFilter(...))
.via(Filters.Translator(...))
.via(myFunction)
.toTarget(myDatabase);
Such an automation script would express the data flow much better than most YAML-style languages: the application reads data from a source like a message queue, routes messages through a filter and translator before passing it through a serverless function that then stores the message in a database. Some languages would even provide additional syntactic sugar, for example by using a JavaScript pipe operator, but I am an old Java head, so for me fluent APIs are already pretty awesome. This implementation underneath this code can deploy the required cloud resources and connect them with message channels or event buses as needed. In OO languages, this kind of API and abstraction is actually quite commonplace.
Expressing the structure of your cloud application this way makes inserting a queue or another filter a single-line change, a desirable characteristic called composability. You might want to replace a source or a target for easier testing, cleverly using composability to aid testability. Now, if that doesn’t sound like we’re bringing proper software engineering to cloud automation…
Once we consider this entirely different view of the system that we are building and running, we can easily see why serverless developers prefer automation languages that are object-oriented. I, for example, am firmly in the CDK camp as all my work is done in serverless. This realization also helps us understand common criticisms of using OO languages for automation:
Object-oriented automation languages aren’t particularly useful if all you do is define a resource graph.
But OO automation languages do shine once you take your programming model beyond just defining a simple resource graph.
Better together ?
To make sure we didn’t gain one aspect at the expense of another, we should ask where the billing hierarchy, security boundary, or availability zones are represented in this programming model. There are two plausible answers: first, fine-grained serverless applications are more likely to run in a single locality or a single account, meaning that a pipeline could be cleanly nested into a resource graph:
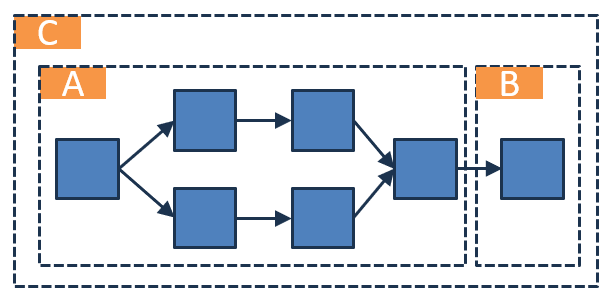
This example may define two pipelines, that run under the respective security roles A and B in the availability zone C.
If the separation between data flow and resource boundaries isn’t that clean, you could fold both definitions into the OO automation language. Funnily, Visual Basic’s With statement springs to mind, but you could also imagine annotations or a coding model that provides both aspects:
p = new pipeline()
.insideRole(Role1,
fromSource(...)
.via(Filters.MessageFilter(...))
.via(Filters.Translator(...)))
.insideRole(Role2,
.via(myFunction)
.toTarget(myDatabase));
To be honest, constructing such pseudo code is difficult for me, so I might just code it out and report back. We do see the mix of nesting and chaining quite clearly in this programming example and some folks who are better with modern languages might even be able to create something much more elegant like the Apache Airflow guys did with the >> operator in Python (you can find the implementation on GitHub).
But what about IfC?
Now that we caught up to about the year-2022-state of automation languages, I should give my views on Infra from Code. Given the rapid evolution of that space, the diversity of approaches, and the word count for this post, I will defer that until the next article–apologies for the cliffhanger!
Before you go, I do want to bestow one more architecture insight upon you, though!
Abstractions Aren’t just about Levels
In a previous post, I elaborated the difference between composition and abstractions, concluding that finding good abstractions isn’t easy. The discussion of automation languages provides us with one additional insight: We realize that to find better abstractions, we can’t just climb the abstraction ladder to find higher-level constructs. Sometimes, the most useful abstraction results from taking a completely different view on the system, kind of like a parallel universe. Considering the focus on lines and data flow versus containment and resource graphs as different universes might explain the heated debates we see when it comes to automation languages. Perhaps infrastructure engineers are from Mars and application developers are from Venus (or from Jupiter or vice versa – you get my point).

A strategy doesn't come from looking for easy answers but rather from asking the right questions. Cloud Strategy, loaded with 330 pages of vendor-neutral insight, is bound to trigger many questions as it lets you look at your cloud journey from a new angle.
Grow Your Impact as an Architect

The Software Architect Elevator helps architects and IT professionals to take their role to the next level. By sharing the real-life journey of a chief architect, it shows how to influence organizations at the intersection of business and technology. Buy it on Amazon US, Amazon UK, Amazon Europe



