
Updated: Category: Cloud
My recent blog posts have touched on cloud abstractions, cloud automation and domain-driven design, and application architecture as code. Cloud automation is a fascinating space and apparently there’s a lot to say about it (each post seems to want to go past 3000 words—thanks for reading!). I therefore continue this unofficial series with an architect’s eye on Infrastructure from Code aka IfC.
Cloud Automation is no longer IaC, but what is it then?
As highlighted in my previous post, much has happened in cloud automation since the advent of IaC (Kief Morris currently working on the 3rd edition of his book Infrastructure as Code provides an additional hint). The following diagram summarizes the key shift:
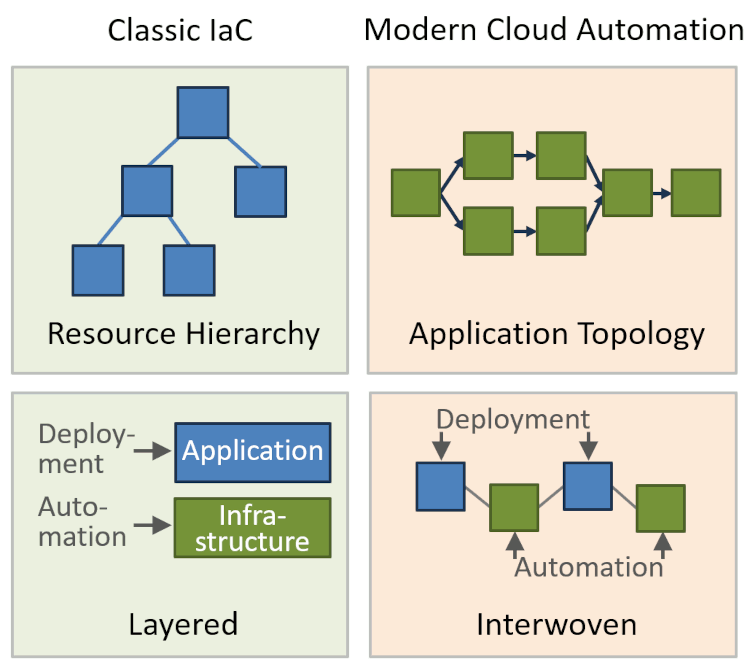
From Resource Hierarchy to Application Topology
- Traditional IaC defines a resource hierarchy that groups services into accounts or virtual private clouds. Relationships between services are weakly modeled by specifying resource URLs as string values.
- In contrast, modern cloud applications, especially serverless applications are fine-grained. The relationship between the components, i.e. application topology, becomes a first-class consideration that should be represented in the automation code.
From Separated Layers to Interleaved Resources
- Traditional automation occurred in a layered model where applications would be deployed on top of infrastructure resources such as virtual machines or Kubernetes clusters. IaC largely concerned itself with the latter whereas CI/CD would handle the former. Application pushes occurred more frequently than infrastructure changes and the two usually didn’t have to be synchronized.
- Modern higher-level services mix up those layers: event routers or orchestration engines, for example, are application-level components whose configuration depends on application data and code. As a result, code deployments and cloud service changes are more likely to occur with the same frequency and have to be kept in sync.
Infrastructure from Code (IfC)
The recent surge in Infrastructure-from-Code tools is driven by this shift: if application code and automation code are more closely interlinked and have to be kept in sync, are separate languages and tools just getting in the way? Could we simply deduce the necessary automation from the application code, perhaps aided by annotations where needed? After all, this is where we ended up with ORM (Object-Relational Mapping), although there are some important nuances, for example, ORM annotations generally don’t provision resources such as the database server.
Why just ignore servers if you can also ignore functions?
One of the early implementations of IfC (that likely predated the term) was Functionless (the site functionless.org is now defunct but the GitHub repo is still active). The core idea was that not worrying about servers is great (aka “Serverless”) but why would developers still have to create and deploy functions using cloud automation? If we could simply write a local method that is transparently deployed as a function to the cloud, we’d have a “functionless” model.
The ideas evolved into eventual, which provides programming abstractions for messaging, choreography, and workflow orchestration—excellent representations for describing distributed systems. Meanwhile that idea is augmented by a natural language description, made possible by generative AI (and perhaps motivated by investor expectations).
Another early entry into the IfC space and the creator of InfrastructureFromCode.com (which aside from the excessive use of “radical” and “ridiculous” is a pretty good site) is Ampt, an extensive framework built around node.js applications. Function invocations can be linked to incoming events, API calls, or data changes:
api.post("/entity", async (req, res) => {
const newData = await data.set(`entity:${req.body}`);
});
data.on("created:entity:*", ({ item }) => {
events.publish("entity.created", { after: "1 day" } item)
});
events.on("user.created", (event) => {
// Delayed update action, e.g. follow-up email
})
One more language to unify them all
Because traditional programming languages often don’t have distributed system concepts built in, some IfC efforts like Wing or DarkLang define new languages. While defining a new language provides enormous flexibility, it also implies a potentially bigger learning curve for developers and significant development effort to assure a well-rounded development environment including IDE with code assist, automated unit tests, debugging, etc. Building a language that includes messages, events, queues etc as first-class constructs (as opposed to a generic library call) aids visualization including round-tripping because more semantics are embedded in the language. Winglang and DarkLang do this as does Ballerina from WSO2. Ballerina dates back to 2015, half a decade before IfC originated as a term, but I’d nevertheless consider it a player in this space.
Other efforts like Klotho shy away from defining a new language and instead use annotations to guide the cloud deployment, not too dissimilar to popular ORM frameworks. My gut feel is that defining a new language is indeed a tall order for both creator and user unless it is very close to existing languages and tooling. Library and annotation-based approaches are therefore worth pursuing. Annotations aren’t without challenges (more on that later), so it’s good to heed the lessons learned with annotation-heavy frameworks like Spring (and calls to the issues with Annotation-Driven Development).
Running local or somewhere else
Most IfC efforts raise the level of abstraction to distributed system concepts like Publish-Subscribe Channels or HTTP endpoints. Doing so not only makes developers more productive, it also decouples the code from the underlying cloud resources. That means that the code can more easily run locally without having to emulate all cloud services. It also makes the code more portable across cloud providers. I decorate an essentially binary property with “more” because cloud platforms aren’t carbon copies of each other, and even simple-sounding concepts like a Queue can exhibit very different run-time characteristics like message retention, batching, polling, dead-letter queues, etc. When running locally, such run-time characteristics can largely be ignored because execution is synchronous. But when deploying to different cloud providers, you’ll find important differences that your code should not gloss over.
Not all IfC efforts aim to be cross-cloud. AWS Chalice plays in the same general arena but is AWS-specific, which allows it to expose specific settings for AWS cloud resources like S3 or SQS with high fidelity, an advantage that’s not to be underestimated when you’re debugging the resources that your tooling generated from your code.
Explicit vs. Expressive: A 2x2 Matrix
In my previous post I proposed a more expressive programming model for serverless applications. How does that approach compare to IfC? The answer lies – I kid you not – in a 2x2 matrix. The most ridiculed tool of management consultants is actually a helpful mental model to better understand the commonalities and differences of competing approaches. If you’re not convinced, consider that IT decisions worth countless Billions of dollars are made based on “magic quadrants”, which are 2x2 matrices.
So, here we have an Infra / Architecture as / from Code 2x2 Matrix:
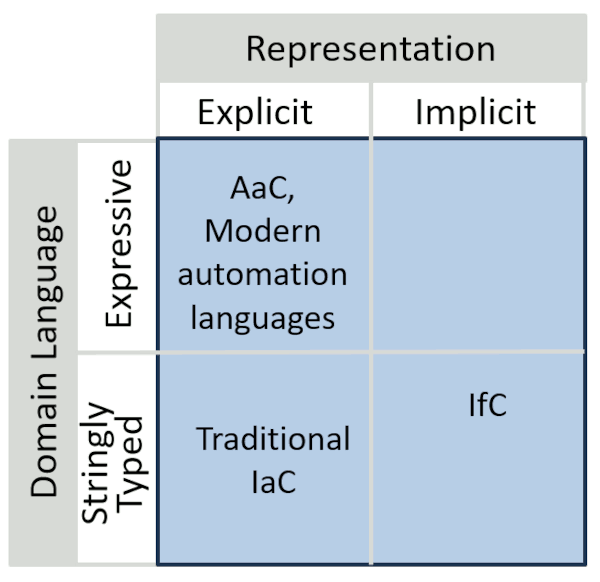
As expected, the distinction occurs across 2 dimensions:
- IaC and AaC (Architecture as Code) approaches make the definition of the application topology and the cloud resources explicit. When you’re coding application code, you’re not provisioning or configuring resources, but when you’re coding automation code you are. Your application code is written against a business domain whereas automation code is written against a technical domain. IfC approaches, in contrast, make the cloud resource description implicit by using the same source for both application logic and resource definition.
- The other dimension describes how expressive the automation description is, e.g. is it based on an explicitly modeled domain with a commensurate programming model or is it largely based on strings, i.e. stringly typed?
Explicit: IaC and AaC
Traditional IaC describes cloud resources explicitly, through code that is separate from application code, whether it’s YAML/JSON or an object-oriented language with libraries like CDK or Pulumi. The difference between traditional IaC and Architecture as Code (AaC) lies in the expressiveness of that description. AaC describes the relationship between application components, wrapped into a strongly typed domain model. IaC, in contrast, focuses on infrastructure elements over applications components and describes the relationships between these elements as strings.
Implicit: IfC
IfC approaches avoid the separate description of cloud resources, making that definition implicit. In some cases, the resources can be determined automatically from the code, for example, a method in source code can be translated 1:1 into a cloud function or an HTTP endpoint can be translated into Lambda URLs (in case of AWS) or an API gateway.
In most cases, those resources require additional settings like security roles or timeouts, which are typically represented as annotations. I therefore positioned IfC slightly below the “expressive” line because in most languages annotations have a weaker type model than application code. Some languages, like Python or JavaScript, don’t provide custom annotations as a language construct, which means they are contained in comment fields (Python 3 supports type annotations but that’s not sufficient for our needs). Even Java, the programming language stalwart of strong (and verbose) typing limits types for custom annotations. IDE support can help with annotations represented as comments or docstrings, but it’s no substitute for a type system. As different IfC tools follow different approaches, we should expect some movement in this area and perhaps see some “above the line”.
Up or out?
The diagram does illustrate nicely that there are two routes (dimensions) to improving cloud automation, or to be more precise, to making it better suited for fine-grained, serverless applications.
- The first route keeps the code explicit but make it more expressive (upwards in the diagram)
- The second route make automation implicit (to the right in the diagram).
The current cloud automation trends can be grouped into “explicit but more expressive” and “implicit”
My previous post posed the question quo vadis, i.e. where are you going, IaC? I think it’s still early days and it might well be that multiple approaches like traditional IaC, IfC and AaC can co-exist. In this case, though, we will need useful guidance as to where to draw the lines between the approaches.
The case for Explicit (AaC)
My current effort takes place in the AaC space, favoring explicit and expressive automation. I selected that route for several reasons:
Distributedness matters (RPC is an illusion!)
Having spent decades in distributed system development, I learned that abstracting away the distributed aspect of the system leads to a dangerous illusion. Time-out windows, retry policies, queue sizes, back pressure, concurrency, flow control, push vs. pull models—they all matter because they determine the run-time behavior of your system. Adding or omitting a Circuit Breaker can make the difference between a resilient system and one that falls over like a house of cards. That’s why I believe that these considerations, which are generally part of serverless integration services, deserve to be represented as first class programming concepts.
Service configuration is a domain of its own
Second, for most serverless integration services the semantic dissonance between configuration data and run-time behavior is huge (that may be a topic for another post altogether). Many services let you set a few string and integer values, behind which lies a complex run-time behavior that you can only (partially!) understand by reading reams of documentation, and finally by trial and error. Modern languages can surely do better than that by modeling the technical domain. Making this configuration explicit eases the design of the associated domain-specific languages. Also, many serverless integration services have their own embedded DSLs (e.g. EventBridge Filters), so that you might end up with a rule languages embedded in a cloud language embedded in an application language—perhaps a bit too much embedding (see my own adventures in serverless-polyglot-low-code-land).
The argument here is mainly about making cloud automation more expressive, assuming that being explicit does allow more expressiveness. Further down, we will challenge / loosen that assumption a bit.
Cloud resources aren’t free
Last, cloud resources aren’t free. One of the run-time properties of your systems is cost, so you might be interested in specifying what resources, how much reserved capacity (yup, even serverless isn’t just “pay per request”), and what pricing model you want. Now, as hinted in my previous post, a cloud compiler might be better at optimizing your costs than you would, just like a code compiler likely generates faster assembly code (Ampt suggests the inclusion of an Architecture Optimizer in its overview). But as that post highlights, good compilers come with an entire ecosystem that includes many optimization settings and stack traces. When a site proudly shows that a few lines of code result in 8 AWS (thank you!) resources being deployed, you do need to wonder how much that will cost.

(apologies to the site owners for picking your example out—the issue is universal)
The case for Implicit (IfC)
I mentioned that I picked expressive over implicit, but that doesn’t mean it’s the superior approach. There are appealing arguments for implicit automation as well:
Application details drive resource choices
Kief Morris, author of the seminal book Infrastructure as Code, highlighted the advantages of implicit automation: many infrastructure settings directly depend on application details. For example, certain types of data like PII (Personally Identifiable Information) or payment data may need to reside in specific locales. Only the application would know which data would fall into which category, so having application logic and cloud automation in the same source files can make it easier to make (and test!) this type of association.
Many of us have experienced the separation between these two aspects (see the shift from layering to interwoven in the first image above) leading to a lot of pain. If the “automation folks” control resources and don’t have any insight into the application characteristics, you’ll end-up with undifferentiated and overly restrictive rules like “no DynamoDB” or “no services in xyz region”, even though DynamoDB would be excellent for product data and xyz region the best place for your API Gateway. Unifying the two concerns promises to alleviate such pain points, assuming that the legacy “automation folks” trust developers to make the right choices (I feel they better do because, hey, if your devs are crooks, you should a) fire them and b) they’ll just tell you “all the data is public” to get you to approve their desired resources).
I very much like Kief’s example because it highlights the linkage between application and cloud resources so well. I am also thinking whether you could expressive automation constructs to express such constraints in explicit automation, perhaps as shown in the following pseudocode:
db = new Database(...).containsPII();
The decorator could then auto-select a region or validate that the specified region permits PII. In any case, it’d very much beat a failed deployment with a cryptic “invalid deployment” error or a manual security review a week before launch.
Productivity
The main argument for IfC, naturally, is developer experience and productivity. Given the shortage of skilled cloud developers and the learning curve of many cloud APIs, anything that can make developers build better cloud applications faster is highly welcome. In some cases, the higher productivity comes at the price of learning an new language or new annotations for an existing language. Only time will tell as developers have to vote with their feet, or rather, their hands.
An area that still causes pain is the integration of cloud automation into the SDLC (I’ll have an entire post on this in the works). Cloud automation has a different lifecycle than application code. If IfC tools can close that gap without making my one-line change (yeah, should have caught that in a unit test but didn’t) a 5 minute deploy, then that’d be an awesome step ahead.
Portability
As mentioned above, many IfC tools also list portability as one of they key benefits. It seems that if you don’t work for one of the “big three”, portability is routinely chosen as David’s sling shot. Portability is always valuable because it’s an option, but my take is that productivity trumps portability: if you aren’t productive (and your competitors are), you’ll have nothing to port (if you feel that my payroll disqualifies me from having opinions on portability, I will point to my convictions being worth a lot more than my salary plus my re:invent talk on lock-in that takes a much deeper and balanced view on the topic).
The following table gives a (simplified) summary. As hinted above, some degree of mixing and matching for as “best of both worlds” solution might be possible.
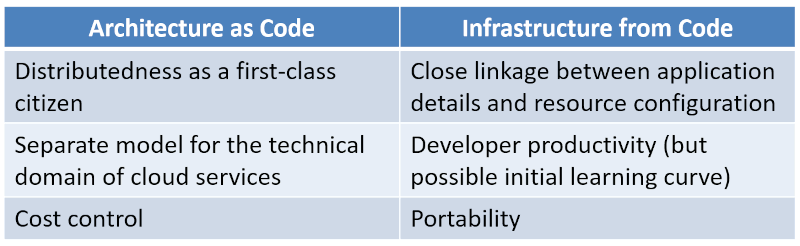
It depends: Focus on the lines or the boxes
IfC approaches tend to focus on the boxes over the lines, as the starting point is the application logic residing in the boxes. As expected, I am biased towards lines - lines determine your application’s topology and its critical characteristics. Modern cloud lines also incorporate a lot of functions like filtering, routing, transformation, schema validation, enrichment. One could almost say they resemble Enterprise Integration Patterns. Describing the lines is separate from the nodes, which favors them having an explicit configuration.
Some of the IfC approaches do model connecting elements explicitly, for example you can do the following in Winglang (slightly abbreviated), perhaps showing the advantages of a custom language over annotations:
let q = new cloud.Queue();
let b = new cloud.Bucket();
q.setConsumer(inflight (m: str) => {
b.put("latest", m);
});
new cloud.Function(inflight (s: str) => {
q.push(s);
});
One could imagine augmenting that Queue with constructs like those proposed in my previous post:
q = new pipeline()
.fromChannel(queue)
.via(Filters.MessageFilter(...))
.via(Filters.Translator(...))
.toTarget(myBucket);
new cloud.Function(inflight (s: str) => {
q.push(s);
});
An interesting space to explore, for sure!
Does GenAI make all this irrelevant?
Architects are known to zoom in and out, so in addition to diving deep into cloud automation we should also look at the broader context. Anything related to developer experience these days can’t ignore Generative AI and AI-based code assist tools. Eventual is making the shift to natural language and most large tech companies have code-assist tools like Amazon CodeWhisperer or GitHub Copilot. The great power of these tools lies in being able to recite the magic incantations for verbose or perhaps less intuitive APIs.
Code assist tools can be a great productivity booster but I don’t believe that they don’t alleviate from the task to design expressive APIs that guide developers towards a correct solution:
APIs are UIs for developers
Two particular considerations are testing and maintenance. For regular application code, unit tests can help assure that the generated code is correct, but for cloud automation such tests are much more difficult to write and therefore often absent. Second, generated code makes developers much more productive, but coding is not a one-time write-only activity. Code evolves over time due to changes in requirements, libraries, development teams, or environments. So, the code that the assistant generates still needs to be easily readable.
As a result, I think that better cloud automation language and API design can go hand-in-hand with code assist tools, allowing us to tackle the problem from both ends.
What next?
Cloud automation is heading for a new round of innovation. We might call it AaC, IfC, IaC 2.0, but it’s clear that we are still at the beginning of that new wave with a lot more ideas to take shape. Stay tuned for the next post!

A strategy doesn't come from looking for easy answers but rather from asking the right questions. Cloud Strategy, loaded with 330 pages of vendor-neutral insight, is bound to trigger many questions as it lets you look at your cloud journey from a new angle.
Grow Your Impact as an Architect

The Software Architect Elevator helps architects and IT professionals to take their role to the next level. By sharing the real-life journey of a chief architect, it shows how to influence organizations at the intersection of business and technology. Buy it on Amazon US, Amazon UK, Amazon Europe



