
Updated: Category: Architecture
In my Architect Elevator workshops, I often reference one of the many wise quotes by Eli Goldrat:
“Technology can bring benefits if, and only if, it diminishes a limitation.”
In simple terms, this means that with the technology we can do something that we couldn’t do (or not as well as) before. Although it sounds rather intuitive, this insight has significant implications on our work as architects. A lot of our assumptions and the heuristics that we apply to arrive at solutions are shaped by constraints. If those constraints diminish, that’s great. But it’ll only let us progress if we can imagine a world without that constraint in place.
The catch is that past constraints are baked into many existing systems, usually without being explicitly acknowledged. My favorite example explains why business units tend to have ridiculously long lists of requirements:
Business users have learned that adding requirements later is impossible or at least very expensive. So, they ask for anything that they could possibly need upfront.
The constraint (requirements are static) shapes the behavior (long lists of requirements). If you remove the constraint, for example through agile ways of working that welcome late changes, the behavior won’t automatically change. That’s because the constraint was baked into the behavior a long time ago, and no one exactly remembers how. That’s one of the reasons why transformation is so difficult.
To make things a little less depressing, I tend to wrap the situation into a bit of humor, which–as so often–is funny only because it’s largely true:
The business has learned that IT on average delivers half of what it promised. So, they figure that by asking for twice as much, with a little luck, they get what they need.
Architects live in the first derivative (a common saying of mine and a chapter in The Software Architect Elevator), so we need to watch out for past constraints that no longer apply. Let’s look at a few examples–as so often, the first one (and the trigger for this post) came from a conversation with friends.
You wouldn’t build your own power station, or would you?
In a recent WSo2 platform engineering podcast with old friends Sanjiva and Frank Leymann, we came upon a common saying about cloud computing, routinely pitched by cloud vendors: that computing, like electricity, is a utility. This, in turn, implies that building your own, whether it’s a power station or a data center, is nonsensical. Perhaps invigorated by being reconnected with old friends, I could not help but burst out:
Well, these days we all do have our own power station: solar-power!
One thing we have a lot of in Asia is sun, so solar-powered lights and water pumps are very common. My garden watering and lighting system is powered by a solar panel, a charge controller, a battery, and several timers:

To add insult to injury, solar panels produce direct current (DC), in my case 12V DC. So, in a strange way, Edison may have won the Current War 140 years later! (many folks use inverters to generate 220V AC from their solar system, which appears a bit silly since most devices use transformers and rectifiers to convert AC back into DC).
In SouthEast Asia, one of the primary benefits of solar power is independence from the power grid, which doesn’t reach rural farms. Shared infrastructure is great, but only as long as there’s sufficient economies of scale for the sharing to happen. This also reminds us that the main benefit of a novel technology (power in remote areas) isn’t always the apparent one (free and carbon-free power).
When I shared this story on LinkedIn, a very on-message solution architect from a major vendor was quick to point out that local operational overhead would always favor centralization. I don’t see this effect for rural solar power. For one, delivery infrastructure is expensive–wireless power is a thing, but it’s not like 5G coverage, which covers a wide area with high-value connectivity. Second, the local operational effort is near-zero. As an experiment, I routinely order dirt-cheap components from AliExpress to see how well they work. After 1 year, both charge controller and timer in the picture (about $8 and $3, respectively) still work fine. The battery will wear down in 2-3 years–AGM batteries don’t like constant heat, and my UPS at home is on the 3rd battery already. That’s not a failure, though, but a predictable and gradual maintenance item.
As architects, we like to contemplate what drove such a shift from central power generation and long-distance distribution to local generation. Two main factors come to mind:
- Componentization: Solar charge systems are composed of well-defined parts, which can be easily procured and swapped if needed. Solar panels, charge controllers, batteries, timers, and inverters are easily combined into a functioning solar-powered watering system.
- Commoditization: Each component has become a commodity, meaning it’s cheap, reliable, and easily obtainable. My low-price experiment confirms that a USD 10 solar cell with a USD 8 charge controller works just fine–the battery is fully charged by about 10am (I’d advise against buying batteries that are too cheap to be true, as it likely is; I paid about USD 24 for my 12V/7.2Ah battery).
Together, these effects countered the inherent scale effect of power generation, at least for small loads. A fossil fuel plant, hydropower, or nuclear power station doesn’t scale down very well (except for military applications), but solar panels work just fine in small installations that power lights, pumps, valves, and circuits.
Once overcome, past constraints are quickly forgotten
When friends and I started a company to build multimedia exercise equipment in the mid-90ies, the lack of broadband infrastructure presented a major design constraint for us. We had to supply video content on CDs, something that’d appear absurd just a few years later when broadband DSL became commonplace. Building a user interface device was also expensive and cumbersome without the luxuries of open-source hardware like Raspberry Pi’s or ubiquitous smartphone devices.
Most of the constraints that hampered our implementation are no longer in place. You could say we were ahead of our time, but that’s where we have to heed the learning from “The Big Short”:
“I may be early, but I’m not wrong” – “It’s the same thing, Michael!”
So, once in a while it’s good to have a look back and appreciate just how far we have come–our industry thrives on removing constraints. And, yes, being too early is also being wrong.
Weakened Constraint: Provisioning Resources
The cloud removed several major constraints. I often remind folks that AWS didn’t invent the data center. But it fundamentally changed how we procure IT resources: near-instant provisioning of resources that you pay for by usage.
A decade-and-a-half later, IT managers still routinely look up the hourly price of a virtual cloud server, multiply it by 720 hours, and compare it to their current hardware cost per month. That approach is ignoring the removal of the constraint entirely. It’s like opening the cage on animals held in captivity for a long time–they are not interested in venturing out.
Without a constraint, the recommended way of working can become the exact opposite.
Once a constraint is alleviated, the recommended way of working can turn into the exact opposite. That’s why it’s so important to rethink old ways of working in the face of shifting constraints. For example, when hardware lead times were long, keeping a server up-and-running as long as possible was common practice (and a matter of personal pride). Once that constraint disappeared, we consider hardware disposable and actually prefer fresh and short-lived servers, as explained in the Cloud Strategy chapter “The new -ility: Disposability”.
Likewise, long procurement lead times and reliance on physical hardware led enterprise IT to adopt a model that seems almost silly once these constraints disappear:
Why would you run software that you did not build?
Enterprise IT was primed to buy loads of hardware based on vendors’ sizing recommendations, install software on it, train staff in operations, but still have no control over feature delivery. Oh, and if something went wrong, it’d be blamed on installation issues or lack of operational skill. Once compute resources became fluid and connectivity ubiquitous, we could see just what a poor deal running other people’s software was.
Weakened Constraint: Server Size
Provisioning isn’t the only compute resource constraint that has dramatically changed. Available hardware size is equally interesting. Most enterprise-scale architectures are based on the assumption that a single machine is insufficient to handle the required workload. Most cloud solutions, especially serverless solutions, are based on the same premise: if you need something to scale, it must be distributed. A secondary driver is resilience: in a distributed, scale-out system, it’s easier to absorb a component failure and thus increase uptime.
The first constraint has weakened substantially in recent years. Compute hardware still grows at Moore’s law, about double the power every 18 months. Regular business hasn’t grown anywhere near that pace–the stock market would love you if you did. And if you’re in public sector, Korea would love to have your birth rate!
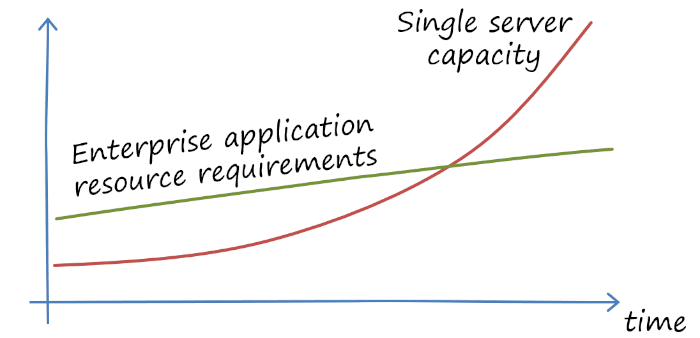
In my time as chief architect at a large insurance company I frequently teased that our core insurance system could run on a beefy laptop for most markets: 100,000 user accounts with mostly static data and infrequent access really isn’t much of a load these days (the nightly batch run without restartability was another story…).
If you haven’t had a look at server hardware in a while (DHH certainly recommends you do), you will find that today’s high-end servers are small data-centers-in-a-box. I arbitrarily picked Dell and found the following specs for a PowerEdge R960:
- 240 cores (4 sockets of 60 cores each)
- 16 TB RAM in 64 DDR5 DIMMs (that’s like 1000 decent laptops)

If you need persistent storage, you can connect up to 24 NVMe drives–at 4 TB each, that’s almost 100TB of high-speed solid state storage. And if you find 240 cores a bit wimpy, Intel announced Xeon Processors with 288 (efficiency) cores. And we’re not talking anything exotic, liquid-cooled here. It’s a motherboard with a few CPU sockets and expansion slots. You can already plug two Xeon 6780 into a 2U PowerEdge R770 server for a total of 288 cores, for a bargain price of around USD 32k.
John O’Hara gave a great talk on this topic at QCon London. I attended, following my rule that one should attend talks that are based on a different viewpoint than your own.
Attending talks presenting a different viewpoint than your own can be a great way to detect outdated assumptions that you hold.
Now, how much operational data does your business application store? 1 megabyte per customer account? 1 million of those (not a bad business!) make a mere 1 TB. We got quite some headroom left–in main memory! 1,000 requests per second against an in-memory database? I almost guarantee you that you got more than a few of cores sitting idle. 10,000 (40 per core / second) or even 50,000 sounds more plausible.
How about resilience? Everything fails all the time, right? At least Werner Vogels said so, but that was back in 2008 when AWS was little more than S3, SQS, and EC2, the latter of which just exited public beta and got an SLA–perhaps there’s a connection here. Modern servers have redundant, swappable power supplies and fans, hot-swappable storage, and some are claimed to have swappable RAM. Still, you won’t keep all your data just in RAM, but write a persistent log that allows you to restore the system state in case of failure. For a large server, that may take time. If you have 2 hardware outages a year and a 30 minute restore time, you still get 4 nines, about the same as most cloud services. In reality, you likely break down your system into smaller components that must be highly available and others that can afford a slightly longer MTTR.
Cloud providers must architect for a scale that you don’t have
When designing for scale, the first law of enterprise IT applies:
No, you’re not Google, Meta, or Temu.
Although e-commerce deals with massive load spikes for holiday shopping or the self-inflicted Cyber Monday, much of the world runs on a few million requests a day, if that. For cloud providers, it’s a different story. Amazon SQS processes “billions of messages per day”, and S3 held 280 trillion objects, processing 100 million requests per second, as of 2023.
This scale does require distributed, asynchronous architectures that are massively scaled out. The catch is that you inherit the programming model for services at that scale, even if your scale is 5 orders or magnitude smaller. When at AWS, I had a common saying to highlight this issue:
What if customers want the functionality, but not the distributedness?
For example, I want event routing and easily deployable functions, but I don’t want asynchronous, out-of-order delivery lacking transactional guarantees that I get with EventBridge and Lambda. Sadly, serverless packages the complex programming and run-time model along with the functionality, one aspect that adds to the serverless illusion, which I highlighted before. As a result, you’re not benefitting from the reduced hardware size constraint, unless you wander back to on premises (hello again, DHH!), or perhaps VMs in the cloud (you can get 24TB RAM in EC2 for about USD 100 per hour, although you’ll have to make do with 2nd generation Xeon processors).
Everyone’s favorite unfavorite: coupling
If you ask architects to quickly name out one of the most important design criteria, there’s one word that you are bound to hear a lot: “coupling”, as in “everything must be loosely coupled”. Now, one could write entire books on the topic, so I will simplify a bit, but the hunt for loose coupling might also be past its prime.
Our love affair with loose coupling is based on the desire to limit change propagation. If a seemingly simple change also necessitates a change in a far-away and ostensibly unrelated component, that’ll slow down development and lead to all sorts of unwelcome behavior like not fixing or refactoring things when needed.
The underlying constraint, which favors loose coupling, is that a) it’s difficult to find the places to change and b) that it’s difficult to make the change. In recent years, we have drastically reduced those constraints, for example through better source code management, global searches, CI/CD, automated tests, and much more. So, we can get away with much more tight coupling than we might be used to (and in fact, this observation led to Gregor’s Law of Coupling).
You can’t take sugar out of the cookies
When I speak to executive audiences about the challenges of transformation, I resort to the following metaphor:
If someone invents sweetener and removes the constraint that sweetness implies calories, you can’t take the sugar out of your cookies–you’ll have to bake another batch.

In large organizations, constraints have been baked into all forms of processes and ways of working, often over the course of multiple decades. Getting those constraints out is equally challenging as getting the sugar out of your cookies.
As architects, we can lead by example to flush out outdated assumptions and heuristics from our brains. And I like baking cookies, so making a new batch is no problem.

Platforms appear to defy the laws of physics by boosting velocity and innovation via standardization and harmonization. Pulling this magic off is harder than it looks, so before you embark on your platform journey, equip yourself with this valuable guide from the Architect Elevator book series.



