
Updated: Category: Cloud
Simple, but evocative decision models help Elevator Architects make better and more conscious decisions. Hybrid cloud is a great test case for this.
As I explained in my previous post on Hybrid-multi Cloud, hybrid clouds are a given in any enterprise cloud scenario, at least as a transitional state. The reason is simple: you’re not going to find all your workloads magically removed from your data center one day - some applications will already be in the cloud while others are still on premise. And more likely than not, those two pieces will need to interact.
So, hybrid has some justification as a buzzword. Still, it can greatly benefit from applying architectural thinking to is. Let’s start with the definition from last time:
Hybrid cloud architectures split workloads across the cloud and on-premises environments. Generally, these workloads interact to do something useful.
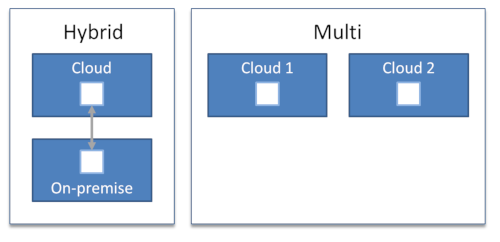
I find simple definitions most useful because we already have to deal with enough complexity when trying to define a sound cloud computing strategy. Simple definitions not only make concepts and decisions accessible to a wide audience, they can also highlight what something is used for instead of focusing on what it’s made from (it may be a pattern author’s natural tendency to focus on intent as opposed to structure).
Alas, defining something is merely a first step – we’ll need to evolve it into something concrete so that it becomes actionable. For that, we take the Architect Elevator a few floors down to understand some important nuances and catalog them.
Two isolated environments don’t make a hybrid
Having some workloads in the cloud while others remain on our premises sadly means that you have just added yet another computing environment to your existing portfolio. I haven’t met a CIO who’s looking for more complexity in his or her shop, so this doesn’t sounds like a great plan.
I haven’t met a CIO who’s looking for more complexity. So, don’t make your cloud yet-another-data center.
Therefore, unified management across the environment is essential to call something hybrid. Think of it in analogy to a hybrid car: The difficult part in making a hybrid car wasn’t to stick a battery and an electric motor into a petrol-powered car. Getting the two systems to work in a seamless and harmonious way were tricky, and that’s what made the Toyota Prius a hybrid.
So, we’ll amend our definition:
Hybrid cloud architectures split workloads across the cloud and on-premises environments. Generally, these workloads interact to do something useful. Both environments are managed in a unified way.
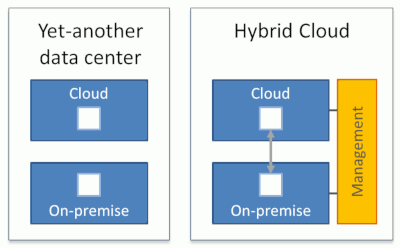
Uniform management across diverse environments isn’t easy, but can be approached in several ways:
- Mimicking the cloud environment on premises, e.g. via AWS Outposts or Azure Stack.
- Replicating your existing on-premise environment in the cloud, e.g. with VMWare Cloud.
- Stretching a uniform run-time and management layer across both environments, e.g. with containers, Kubernetes, and a management layer like Google Anthos.
- Making cloud data easily available from on-premises environments via AWS Storage Gateway or various storage replication solutions like NetApp SnapMirror.
- Integrating identity and access management, e.g. by integrating cloud accounts with Active Directory.
Come to think of it, there’s plenty enough material just in those decisions to justify a separate post. So, let’s park this for a moment and go back to the fundamental decision of hybrid cloud: what goes out and what stay in?
Splitting Workloads - 31 Flavors?
The key architectural decision of hybrid cloud is how to split your workloads, i.e. which parts of your IT landscape to move into the cloud and which parts to keep on premises. This decision is closely related to the notion of finding seams in an IT system, first described (to my knowledge) by Mike Feathers in his classic book Working Effectively with Legacy Code. Seams are those places where a split doesn’t cross too many dependencies and doesn’t cause run-time problems, for example performance degradation.
I don’t think I’ll be able to quite come up with 31 ways to split workloads, so I apologize for the click-baity title. Still, I want to attempt to catalog as many of them as I can. It’ll be helpful in several ways:
- A common vocabulary gives decision transparency because it’s easy to communicate which option(s) you chose and why.
- The list also allows you to check whether you might have overlooked some options. Especially in environments where regulatory concerns and data residency requirements still limit some cloud migrations, a handy playbook allows you to check whether you exhausted all possible options of moving things to the cloud.
- Lastly, having a clear set of options makes it easier to consider applicability, pros, and cons of each option in a consistent way. It’ll also tell you what to watch out for when selecting a specific option.
Hybrid Cloud: Ways to Slice the Elephant
I could think of at least eight common ways that enterprises split their workloads across their hybrid environments. You may have even seen more:

This list’s main purpose isn’t as much to find new options that no one has ever thought of. It’s much rather a collection of well-known options that makes for a useful sanity check. Let’s have a look at each approach in a bit more detail.
Tier: Front vs. Back
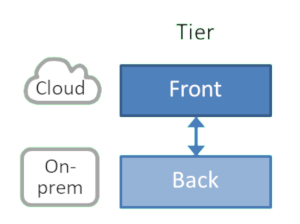
Moving customer or ecosystem-facing components, aka “front-end systems” / “systems of engagement” to the cloud while keeping back-end systems is a common strategy. While you won’t see me celebrating two-speed architectures, multiple factors make this approach a natural fit:
- Front-end components are exposed to the internet, so routing traffic straight from the internet to the cloud reduces latency and eases traffic congestion on your corporate network.
- The wild traffic swings commonly experienced by front-end components make elastic scaling particularly valuable.
- Front-end systems are more likely to be developed using modern tool chains and architectures, which make them well suited for the cloud.
- Front-end systems are less likely to store personally identifiable or confidential information because that data is usually passed through to back-ends. In environments where enterprise policies restrict such data from being stored in the cloud, front-end systems are good candidates for moving to the cloud.
Besides these natural advantages, architecture wouldn’t be this interesting if there weren’t some things to watch out for:
- Even if the front-end takes advantage of elastic scaling, most back-ends won’t be able to absorb the corresponding load spikes. So, unless you employ caching or queuing or can move computationally expensive tasks to the cloud, you may not improve the scalability of your end-to-end application.
- Similarly, if your application suffers from reliability issues, moving just one half to the cloud is unlikely to make those go away.
- Many front-ends are “chatty” when communicating with back-end systems or specifically databases because they were built for environments where the two sit very close to each other. One front-end request can issue dozens or sometimes hundreds of requests to the back-end. Splitting such a chatty channel between cloud and on-premises is likely to increase end-user latency.
As the excitement of “two speed IT” wore off, this approach can still be a good intermediary step. Just don’t confuse it for a long-term strategy.
Generation: New vs. Old
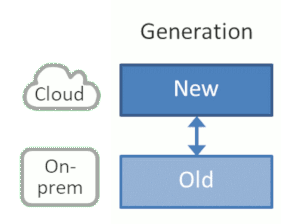
Closely related is the split by new vs. old. As explained above, newer systems are more likely to feel at home in the cloud because they are generally designed to be scalable and independently deployable. They’re also usually smaller, making them deserving of the label cloud native, even though it’s not my favorite term as it appears to prohibit cloud (im)migration.
Again, several reasons speak for this type of split:
- Modern components are more likely to use modern tool chains and architectures, such as micro-services, continuous integration (CI), automated tests and deployment, etc. Hence they can take better advantage of cloud offerings.
- Modern components are more likely to run in containers and can thus utilize higher-level cloud services like managed Kubernetes or serverless environments.
- Modern components are more likely to be well-understood and tested, reducing the migration risk.
Again, there are a few things to consider:
- Splitting by new vs old may not align well with the existing systems architecture, meaning it isn’t hitting a good seam. For example, splitting highly cohesive components across data center boundaries will likely result in poor performance.
- Unless you are in the process of replacing all components over time, this strategy doesn’t lead to a “100% in the cloud” outcome.
Overall this is a good approach if you are developing new systems - ultimately new will replace old.
Criticality: Non-critical vs. Critical
Many enterprises prefer to first dip their toe into the cloud water before going all out. They are likely to try the cloud with a few simple applications that can accommodate the initial learning curve and the inevitable mistakes. “Failing fast” and learning along the way makes sense:
- Skill set availability is one of the main inhibitors of moving to the cloud - stuff is never as easy as shown in the vendor demos. Therefore, starting small and getting rapid feedback builds much needed skills in a low-risk environment.
- Smaller applications benefit from the cloud self-service approach because it reduces or eliminates the fixed overhead common in on-premise IT.
- Small applications also give you timely feedback and allow you to calibrate your expectations.
While moving non-critical applications out to the cloud is a good start, it also has some limitations:
- Cloud providers generally offer better uptime and security than on-premises environments, so you’ll likely gain more by moving critical workloads.
- While you can learn a lot from moving simple applications, they may not have the same security, up-time, and scalability requirements as subsequent workloads. You therefore need to be cautious to not under-estimate the effort of a full migration.
Overall it’s a good “tip your toe into the water” strategy that certainly beats a “let’s wait until all this settles” approach.
Lifecycle: Development vs. Production
There are many ways to slice the proverbial elephant (eggplant for vegetarians like me). Rather than just considering splits across run-time components, a whole different approach is to split by application lifecycle. For example, you can run your tool chain, test, and staging environments in the cloud while keeping production on premises, e.g. due to regulatory constraints.
Shifting build and test environments into the cloud is a good idea for several reasons:
- Build and test environments rarely contain real customer data, so most concerns around data privacy and locality don’t apply.
- Development, test, and build environments are temporary in nature, so being able to set them up when needed and tearing them back down leverages the elasticity of the cloud and can cut infrastructure costs by a factor of 3 or more: the core working hours make up less than a third of 168 hours in a week. Functional test environments may even have shorter duty cycles, depending on how quickly they can spin up.
- Many build systems are failure tolerant, so you can shave off even more Dollars by using preemptible / spot compute instances.
You might have guessed that architecture is the business of trade-offs, so once again we have a few things to watch out for:
- Splitting your software lifecycle across cloud and on-premises results in a test environment that’s different from production. This is risky as you might not detect performance bottlenecks or subtle differences that can cause bugs to surface only in production.
- If your build chain generates large artifacts you may face delays or egress charges when deploying those to your premises.
This option may be most popular for development teams that are restrained from running production workloads in the cloud but still want to take as much advantage of it as possible.
Data Classification: Non-sensitive vs. Sensitive
The compute aspect of hybrid cloud is comparatively simple because code can easily be re-deployed into different environments. Data is a different story: data largely resides in one place and needs to be migrated or synchronized if it’s meant to go somewhere else. If you move your compute and keep the data on premises, you’ll likely incur a heavy performance penalty. Therefore, it’s the data that often prevents the move to the cloud.
As data classification can be the hurdle for moving apps to the cloud, a natural split would be to move non-sensitive data to the cloud while keeping sensitive data on premises. Doing so has some distinct advantages:
- It complies with common internal regulations related to data residency as sensitive data will remain on your promises and isn’t replicated into other regions.
- It limits your exposure in case of a possible cloud data breach.
However, the approach is rooted in assumptions that don’t necessarily hold true for today’s computing environments:
- Protecting on premises environments from sophisticated attacks and low-level exploits has become a difficult proposition. For example, CPU-level exploits like Spectre and Meltdown were corrected by some cloud providers before they were announced - something that couldn’t be done on premises.
- Malicious data access and exploits don’t always access data directly but often go through many “hops”. Having some systems in the cloud while your sensitive data remains on premises doesn’t automatically mean your data is secure. For example, one of the biggest data breaches, the Equifax Data Breach that affected up to 145 million customer records had data stored on premises.
Hence, while this approach may be suitable to getting started in face of regulatory or policy constraints, use it with caution as a long-term strategy.
Data Freshness: Back-up vs. Operational
Not all your data is accessed by applications all the time. In fact, in many enterprises a vast majority of data is “cold”, meaning it’s accessed rarely. That’s the case for example for historical records or back-ups. Cloud providers offer appealing options for data that’s rarely accessed. Amazon’s Glacier was one of the earliest offerings to specifically target that use case while other providers have special tiers for their storage service, e.g. Azure Storage Archive Tier and GCP Coldline Cloud Storage .
Archiving data in the cloud makes good sense:
- Backing up and restoring data usually occurs separate from regular operations, so it allows you to take advantage of the cloud without having to migrate or re-architect applications.
- For older applications, data storage cost can make up a significant percentage of the overall operational costs, so moving some of this to the cloud can give you instant cost savings.
- For archiving purposes, it’s good to have data in a location separate from your usual data center.
Alas, it also has limitations:
- Data recovery costs can be high, so you’d only want to move data that you rarely need.
- The data you’d want to back up likely contains customer or other proprietary data, so you might need to encrypt or otherwise protect that data, which can interfere with optimizations such as data de-duplication.
Still, using cloud backup is a good way for enterprises to quickly start benefiting from the cloud.
Operational State: Disaster vs. BAU
Lastly, one can split workloads by the nature of the system’s operational state. The most apparent division in operational state is whether things are going well (“business as usual”) or whether the main compute resources are unavailable (“disaster”). While you or your regulator may have a strong preference for running systems on premises, when these systems have become unavailable, it may be better to have a running system at all, even if it’s located in the cloud.
This approach to slicing workload is slightly different from the others as the same code would run in both environments, but under different circumstances:
- No workloads run in the cloud under normal operational conditions.
- Cloud usage is temporary, making good use of the cloud’s elastic billing approach.
However, life isn’t quite that simple:
- In order to run emergency operations from the cloud, you need to have your data synchronized into a location that’s both accessible from the cloud and unaffected by the outage scenario that you are planning for. More likely than not, that location may be the cloud, at which point you might consider running the system from the cloud in any case.
- Using the cloud just for emergency situation deprives you of the benefits of operating in the cloud in the vast majority of the cases.
So, this approach may be most suitable for compute tasks that don’t require a lot of data. For example, for an e-commerce site you could allow customers to place orders even if the main site is unavailable by picking from a (public) catalog and storing orders until the main system comes back up. It’ll like beat a cute 404 or 500 page.
Workload Demand: Burst vs Normal Operations
Last, but not least, we may not have to conjure an outright emergency to occasionally shift some workloads into the cloud while keeping it on premise under normal circumstances. An approach that used to be frequently cited is bursting into the cloud, meaning you keep a fixed capacity on premises and temporarily extend into the cloud when additional capacity is needed.
Again, you gain some desirable benefits:
- The cloud’s elastic billing model is ideal for this case as short bursts are going to be relatively cheap.
- You retain the comfort of operating on premises for most of the time.
But there’s reasons that people don’t talk about this option quite as much anymore:
- Again, you need access to data from the cloud instances . That means you either replicate the data to the cloud, which is likely what you tried to avoid in the first place, or your cloud instances need to operate on data that’s kept on premises, which likely implies major latency penalties.
- You need to have an application architecture that can run on premises and in the cloud simultaneously under heavy load – not a small feat.
This option likely works best for compute-intensive workloads, e.g. simulations. It’s also a great fit for one-time compute tasks where you rig up machinery in the cloud just for one time. For example, this worked very well for the New York Times digitizing 6 million photos or for calculating pi to 31 trillion digits.
Putting it into Practice
For most enterprises hybrid cloud is inevitable, so you better have a good plan for how to make the best use of it. Because there are quite a few options to slice your workloads across the cloud and your on-premises compute environments, cataloging these options helps you make well-thought-out and clearly communicated decisions. It also keeps you from wanting to proclaim that “one size fits all” – all aspects of being a better architect.
Happy slicing and migrating!
ps: if you haven’t seen it yet, have a look at Simon Wardley’s humorous take on hybrid cloud
More thoughts on cloud strategy:
- Multi-hybrid Cloud: An Elevator Architect’s View
- Don’t run software you didn’t build
- Increasing your “Run” budget may be a good thing [Linkedin]
- Cloud computing isn’t an infrastructure topic [LinkedIn]
NOTE: As a devout vegetarian, I certify that no elephants were harmed in the production of this article nor any related cloud migrations.

A strategy doesn't come from looking for easy answers but rather from asking the right questions. Cloud Strategy, loaded with 330 pages of vendor-neutral insight, is bound to trigger many questions as it lets you look at your cloud journey from a new angle.



