
Updated: Updated: Cloud
Design patterns have long been a useful tool for designing software, allowing developers to describe common solutions and design trade-offs independent from the underlying technology or implementation. Such patterns can be implemented using standard constructs of the language or platform they are mapped onto. In some cases, the patterns are already built into the platform to support a common use case. For example, most integration and cloud platforms will implement a Point-to-Point Channel.
Design patters provide a technology-neutral vocabulary to describe common solutions and design trade-offs
Many influential pattern books like Design Patterns (GoF), 1995, Pattern-Oriented Software Architecture (POSA, 1996), Patterns of Enterprise Application Architecture (PofEAA, 2002), and Enterprise Integration Patterns (EIP, 2003) were published in the mid-90s to mid-2000s when writing complex enterprise applications in Java and C# became popular. Just like many other software concepts, patterns also experienced some ups and downs over the decades. The period of reduced interest (let’s avoid the term “Pattern Winter”) in subsequent years could be attributed to the belief that frameworks preempted most critical architecture decisions, leaving developers to just fill in a few lines of JavaScript here and there. Recent years have seen a renewed interest in software architecture and design patterns (e.g., Microservices Patterns, 2018), perhaps due to applications adopting more sophisticated run-time architectures thanks to being supported by powerful cloud run times.
Patterns for Distributed Systems
Thanks to being technology-neutral, many design patterns passed the test of time despite rapid technology evolution. I recently published a series of blog posts describing serverless solutions using Enterprise Integration Patterns from nearly 20 years ago. Serverless solutions are fine-grained and distributed, so it seems natural that asynchronous messaging patterns help us think through such designs.
Despite enormous progress in automating infrastructure and providing fully managed services, many of the challenges of distributed systems remain: partial failure, latency, message redelivery, positive feedback loops, to name a few. And just like two decades ago, design patterns help us avoid such pitfalls and better understand design trade-offs.
But besides remaining useful in system design, patterns can also be valuable in new contexts, specifically multi-cloud and lock-in.
More Cloud == More Lock-in?
Developers’ and architects’ excitement about all the amazing cloud services can be dampened these days by a (at least perceived) conflict: we favor fully-managed cloud services because they relieve us from the “undifferentiated heavy lifting”: installing, configuring, and patching networks, virtual machines, and the applications running on them. But do those applications that utilize more managed services also become more dependent on the specific cloud platform that they operate on? In short, do they “lock us in”?
This trade-off is a painful one. Thanks to the wide spectrum of vendor-operated cloud services, ranging from storage and data bases to API gateways, orchestrators, event routing, and queuing, building modern applications has evolved into a combination of writing application logic and configuring managed cloud components. So it’d seem silly to build applications on the cloud but to forgo its most powerful services. Still, portability is a valid architecture concern and a valuable option to have.
One of architects’ favorite and most valuable maneuvers is seeing more dimensions, so let’s see if there’s an elegant way out of this situation, or at least a way to take off the pressure.
Beware of Mental Lock-in
When I originally wrote about lock-in on Martin Fowler’s site (the article later evolved into a chapter in Cloud Strategy), I broke lock-in down into several dimensions, for example to highlight that open source only avoids some forms of lock-in (vendor), but not others (product, architecture). The last form of lock-in in that list is labeled as “the most subtle, but also the most dangerous type”: mental lock-in.
Mental lock-in comes in two flavors. For one, past experiences can subliminally instill assumptions into your thinking that prevent you from adoption modern (or different) architectures. Second, technology platforms can make you think in platform components as opposed to solution constructs. This isn’t necessarily bad as it keeps you close to reality, e.g. it’s OK to describe your design as using a java.util.ArrayList as opposed to an abstract list concept. However, when describing your solution by the platform or language components, one runs the risk of losing the original intent. For example, you might have intended to use that List as a circular buffer or a queue.
Ironically, this effect is exacerbated when the underlying platform becomes more powerful, as is the case with the cloud. Cloud platforms (and its vendors along with the published icon kits) particularly tempt you to describe your solutions by the list of services you used. I have pointed out before that architects need to do more than list ingredients, so we should consider this a slippery slope. And in this case the slope leads to mental lock-in.
After translating what I intentionally vaguely call “needs” (you might say “requirements”) into a concrete solution, expressed via the technical platform services, it becomes hard to imagine that solution built on another platform (illustrated using two arbitrarily chosen platforms):
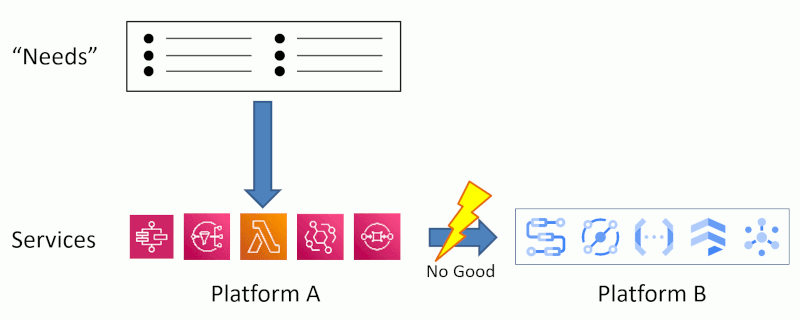
Once you express your architecture only by the technical ingredients, you lose the intent behind what you designed and built. And that makes it very difficult to express your architecture using different tools. That’s why I often joke, don’t tell me “my architecture is Oracle” (that might be a fine choice). Instead, tell me what key characteristics you needed to achieve and what decisions you made to achieve them: is this architecture distributed, replicated, tiered, monolithic, or based on stored procedures (I hope not).
Thinking only in platform services loses your application’s design intent and mentally locks you in
“Hold on”, you might say, all these cloud services map onto other platforms, and most vendors even publish fancy service mapping tables. Yes, they fundamentally do, in a way that EC2, Compute Engine, and Azure Virtual Machines all essentially provision virtual machines. However, there are some severe limitations:
-
For higher-level services, the choice of service does not express much about the application’s needs or the architect’s intent. For example, you might be using Amzon EventBridge to route events, transform messages, or implement a pub-sub channel. In GCP, the former can be done in EventArc (the proposed mapping), the next would need a Cloud Function, and the last would likely find a home in Pub-Sub. Without knowing what you were trying to achieve, no one can recommend the matching service.
-
The list of the individual services isn’t a suitable description of a platform–see my post about fruit salads (yes, it’s relevant). Much of the power of the platform lies in the cohesion across services. This aspect is entirely missing from the mapping tables.
-
The service capabilities, especially for higher level services, don’t correspond 1:1, making any mapping at best an approximation. For example, Step Functions will happily support parallel execution whereas in Google Workflows that’s still an experimental feature.
To illustrate, let’s say your serverless application uses DynamoDB, a nifty serverless NoSQL database with predictable latency. A typical service mapping will tell you to use Google Firestore in Datastore Mode (I am not making these names up). If all you’re doing is writing and reading records, that might be alright. But if you’re using specific commands to append to a data set, perhaps because you’re collecting serverless events, things suddenly look very different.
Cloud platform service mapping catalogs don’t really work
These examples aren’t isolated but are quite typical, especially in the serverless ecosystem, which is rightly considered the most powerful way to use the cloud. So, let’s try something else.
Abstraction Layers = –Lock-in?
Generally, if software engineers want to reduce dependency on something, they add a level of indirection. This technique has been employed to the point that it has been labeled the Fundamental theorem of software engineering:
“There’s no problem in computer science that cannot be addressed with one more level of indirection” –Andrew Koenig
And, indeed we know of some excellent examples. SQL springs to mind: more or less any relational database supports SQL, making it easier to switch from one database to another. It isn’t surprising, then, to see industry initiatives (and countless millions of marketing Dollars) being invested in abstraction layers that are intended to reduce cloud platform lock-in. In fact, SQL is often cited as a role model or as “proof” that the approach works. As many readers already know, I can never quite get over the fact that solutions that avoid native cloud services are marketed as “native” (it’s in direct contrast to how we label for example native mobile applications).
Such abstraction layers look roughly like this:
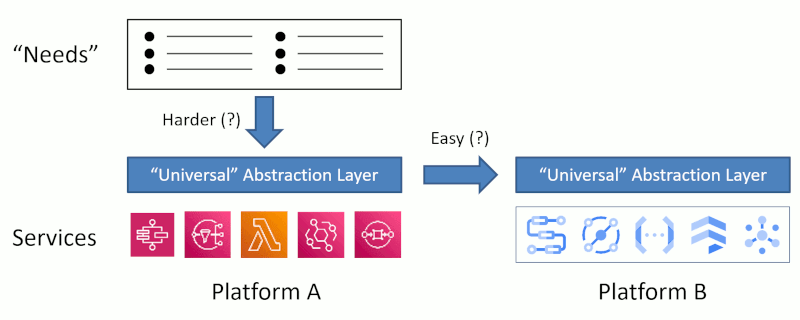
I appreciate the intent but also caution that wanting to fabricate a new abstraction layer is very different from how SQL came about:
- SQL was developed by one vendor, IBM, for a specific product.
- SQL’s goal was to make interacting with relational databases easier, not to achieve portability.
- SQL rests on a solid computational model, relational algebra.
- Virtually every vendor includes proprietary SQL extensions.
- The language cannot shield you from underlying run-time considerations. Tuning a DB will vary profoundly with the product you use—you can’t abstract the laws of physics or failure with a logical layer.
Looking for a common programming interface or API as an afterthought can easily lead to a lowest-common-denominator effect, which is highly undesirable in an area that is undergoing rapid innovation. Or, one ends up with a partial solution, which then won’t achieve portability. Last, the abstraction runs the risk of being more complex, which means we don’t gain (or rather lose) unless we actually migrate. That means, the option becomes rather expensive.
SQL wasn’t developed for portability but to make programming easier
That doesn’t mean abstractions are bad. But they have to be carefully chosen such that they boost your productivity today, not just in the potential case of a future migration.
Patterns: Design-Time Abstractions
The discussion so far assumes that an abstraction layer is a run-time construct, something something that you code against and that’s built and deployed into the running software. As architects, we should see more dimensions™, so what if those abstractions were purely design-time constructs, something that helps us to design better solutions, without burdening our run-time with extra layers and overhead? Compilers have been doing exactly that for decades: we can work in a higher level abstraction that the underlying runtime knows little about. And after compilation, the machine code runs natively (in the true meaning of the term) on the respective platform.
Cloud cross-compilers might still be a ways away, but weren’t we just talking about technology-neutral design-time vocabulary just a few sections ago? Right, that’s what design pattern are!
Patterns reduce lock-in
So could expressing your designs in patterns make it easier to take your application and move it to another platform, even though it’s coded against the original platform’s services? I think so. During my experience implementing the Loan Broker example on GCP, having a clear view of the application expressed as patterns gave me a much better starting point:
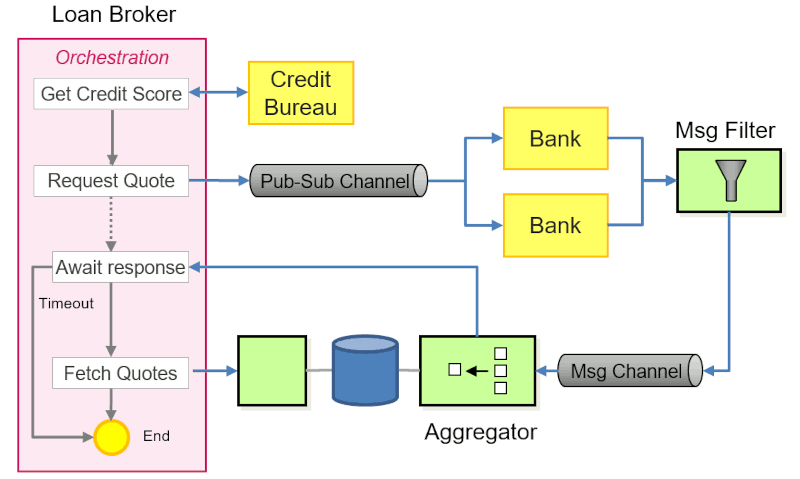
In some cases, a pattern maps almost directly to a service, e.g. a Process Manager maps well to Step Functions, or a Publish-Subscribe Channel maps likely onto SNS, AWS’ Simple Notification Service. However, that’s not always the case. For example, I might need a workflow construct that Step Functions cannot handle (incoming event correlation might be an example) and I have to build that using Lambda and DynamoDB. Alternatively, I can also use EventBridge as a Publish-Subscribe Channel with small fan-out by providing multiple targets.
The Aggregator is another great example. Step Functions doesn’t handle multiple incoming events well, so I use Lambda plus DynamoDB, benefiting from DynamoDB’s atomic list_append function. As I explained in my blog, GCP’s data store doesn’t have an equivalent function, so I need to use transactions and enable retries on the message channel. Knowing that I am building an Aggregator allowed me to abstract some of the key parameters of the patterns (e.g. the completeness condition) from these implementation details.
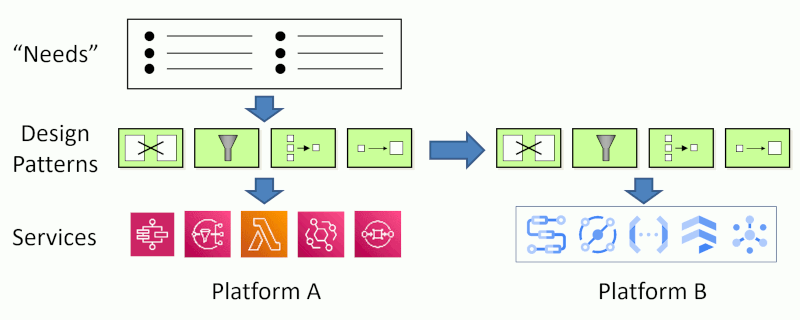
Expressing your solution as design patterns simplifies porting it to another platform
I can also take the pattern approach a step further and code an abstract Aggregator class. That way, I would have to port the logic that very much depends on platform features only once as opposed to having to reverse-engineer it from the current solution. Not every pattern makes a good component, though–I shared my thoughts on Patterns vs. Components some 18 years ago.
A Hint of Run-time?
If you followed my previous posts on Enterprise Integration Patterns, you have learned that automation code can help express design patterns that don’t match to a specific service. For example, using AWS CDK you could provision a Lambda function and an associated DynamoDB to implement an Aggregator. On another cloud platform, you might deploy different components, based on the same pattern abstraction.
Automation code is neither design-time nor run-time code, it’s perhaps best described as deployment time. Being able to express design elements like patterns as object-oriented constructs in deployment-time code is quite a feat that only serverless cloud platforms can deliver.
Serverless cloud platforms allow us to express design patterns in object-oriented constructs for automated deployment
Where from here?
If patterns really make useful design abstractions, which patterns should you use and how can we find more patterns for this purpose? Design patterns are tied to the run-time and composition model of your application. That’s why we have object-oriented design patterns like Singletons and Visitors, as presented in GoF and POSA, and different patterns like Aggregators and Message Filters for message-oriented systems, as described in EIP. It’s OK to use multiple pattern languages, but it’s helpful to have a clear view of which aspect of your system you are applying the patterns to. For example, you could use object-oriented patterns to build your components (e.g. using a Facade), use API Patterns to design the common APIs (you might want to check out an upcoming book), structure your services using Microservices Patterns, and design the data flow using Enterprise Integration Patterns.
Finding suitable pattern languages isn’t easy. A single pattern won’t improve your system design (nor make it portable)—you’ll need a complete language that forms a cohesive vocabulary. Also, when looking for abstractions, it’s all too tempting to start with the platform services you already know and simply combine them (CDK constructs like Lambda, SQS, Lambda are a typical example). That’s useful, but it doesn’t create patterns.
Convenience functions to bundle multiple resources rarely form useful abstractions or patterns
Instead, a pattern language expresses the developer’s intent in a service-neutral language. For example, a related pattern is Competing Consumers, which coincidentally is also featured in Azure’s Architecture Center (and even outranks my site on a popular search engine…).
Serverless Pattern Languages
Serverless systems follow common distributed system design patterns - that’s why I was able to express the Serverless Loan Broker Design so easily using 20-year-old patterns.
However, advances in compute platforms influence the trade-offs that patterns have to make. For example, high levels of automation and seamless scalability, as we find them in the cloud, might favor different patterns than we had in the days of EAI. The catch is that patterns cannot be invented, they are “harvested” from actual widespread use. I am very keen to harvest new serverless patterns. I will spend more time building serverless solutions, but I am equally happy to hear suggestions—connect with me on social media via the links below.

A strategy doesn't come from looking for easy answers but rather from asking the right questions. Cloud Strategy, loaded with 330 pages of vendor-neutral insight, is bound to trigger many questions as it lets you look at your cloud journey from a new angle.
Make More Impact as an Architect

My book The Software Architect Elevator helps architects and IT professionals play at the intersection of technology, organization, and transformation by sharing the real-life journey of a chief architect. Buy it on Amazon US, Amazon UK, Amazon Europe

